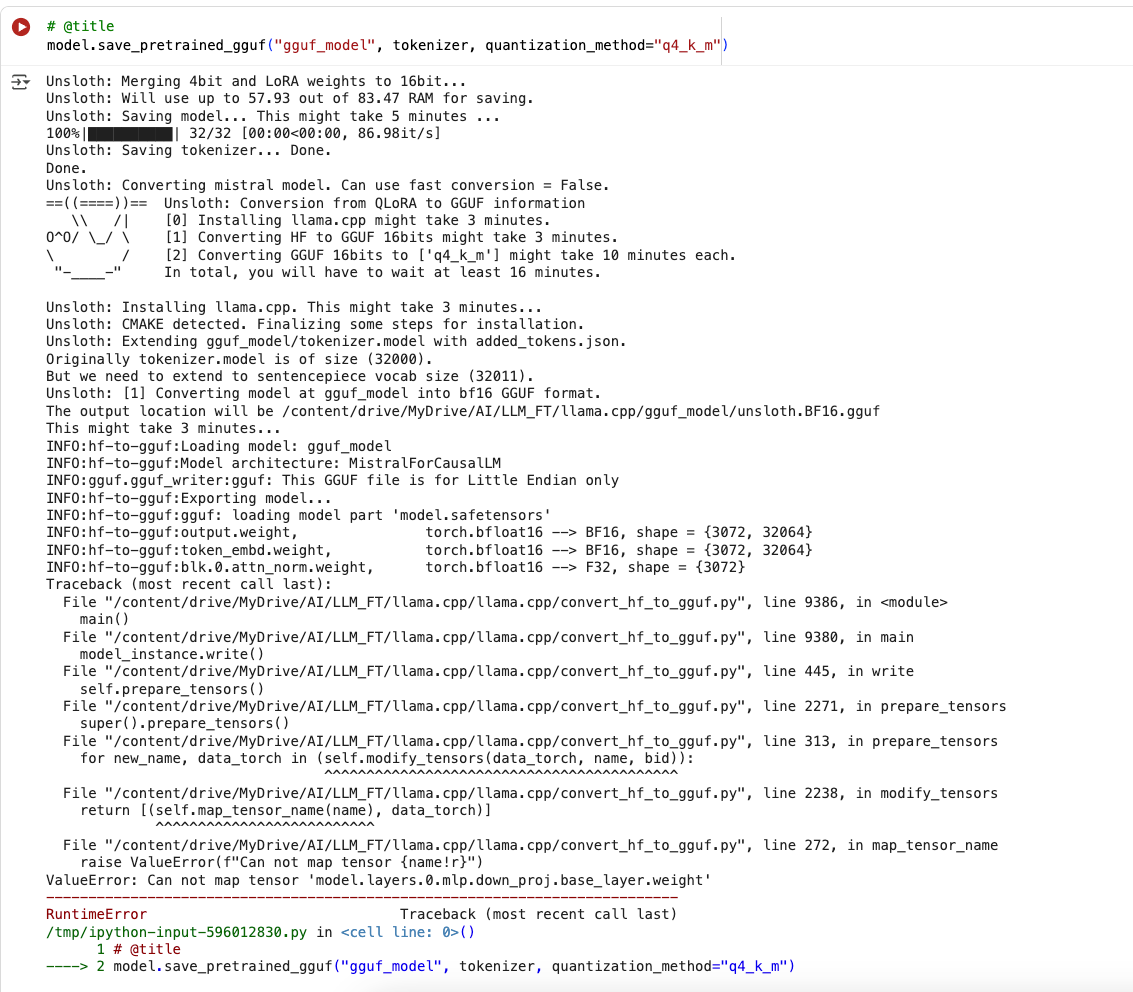
An easy way to Fine Tune

Last night I came across a wonderfully helpful and straight-forward tutorial on fine-tuning LLMs, using Unsloth, an OS framework for LLM fine-tuning and RL. The whole goal of Unsloth is to train, run, and evaluate/save models like Llama, Deep Seek, Mistral, etc., 2x faster with 70% less VRAM.
Walking through the tutorial, here's everything I learned:
Computation is worth it.
I’ve been spoiled to have GPU servers at my convenience both during UMBC and at Booz. But, now, since I’m running this on my personal machine, I decided to purchase a Google Colab Pro+ subscription. I kind of feel like an ad, but now with Colab I can summon an A100 or better - whenever they’re available - at a flat, monthly rate at ~$50. I was going to use Lambda Cloud, but I thought for basic learning, this was easy enough.

Low-Rank Adaptation (LoRA)
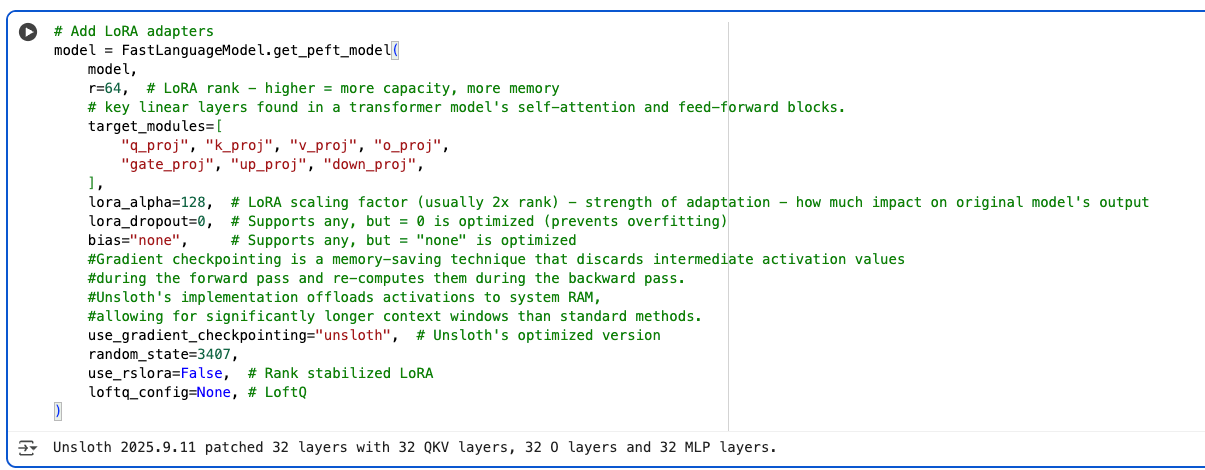
Unsloth uses Low-Rank Adaptation (LoRA), which is a popular choice for fine-tuning and has been around for a few years now. LoRA essentially adds small, trainable “adapter” matrices to existing layers in a transformer. Lots of industry frameworks use this like NVIDIA’s Nemo. You’ll see this in the code like this for Unsloth, in their Phi-3B model, where the below are targeted for LoRA and are a combo of attention and feed-forward layers.
target_modules=[ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", ],
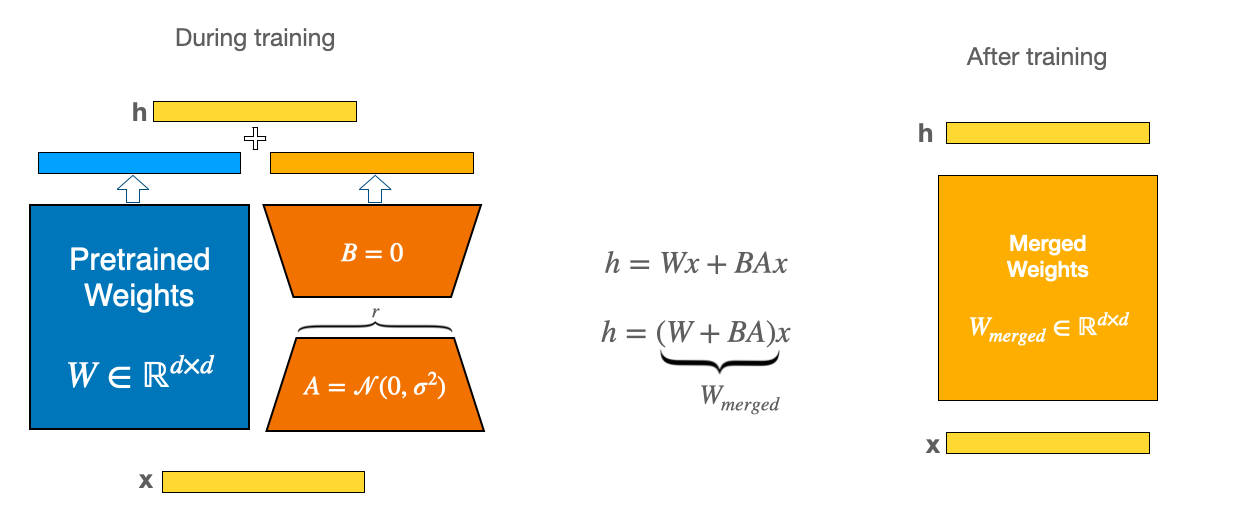
Anyway, the whole goal is to train two small “low rank” matrices (say, A and B), then after training, combine the adapted weights and original weights together. You’ll discover this in more granular code when you “merge” a LoRA adapter with a base model. This is not fun. But Unsloth abstracts it away when you get the FT’d model and convert it into a gguf file.
Anyway, I digress. The training data to FT, involved 500 pairs of the HF stackoverflow-dataset that I converted from .tsv -> .json and used Cursor to enrich it with additional categories. The train and test dataset are below.
After processing, it has the standard
###input” and “###output” and “<|endoftext|> tags that are normal formatting patterns for FT LLMs, in the instruction format, like so:
### Input: Unable to install python-recsys module I am trying to install python-recsys module. But i get this error Could not find a version that satisfies the requirement python-recsys (from versions: ) No matching distribution found for python-recsys I am using Python 3.4 The code that i am using to install the module is: pip.exe install python-recsys\n### Output: {"classification": {"label": 0, "confidence": 0.85}, "content_analysis": {"languages": ["python", "regex"], "topics": ["debugging", "ui_ux"], "question_type": ["why_not_working"], "has_code": false, "complexity": "medium"}, "metadata": {"word_count": 55, "is_question": false, "source_id": "35956868"}}<|endoftext|>’
Manual backprop and Triton Kernels
Now about that speed-up in FT’ing with Unsloth. If you take a look at "https://github.com/unslothai/unsloth/blob/main/unsloth/kernels/fast_lora.py", you’ll see the secret sauce. Basically, it manually derives (chain rule anyone?) backprop and rewrites all Pytorch modules into Triton kernels. This makes it reduce memory usage and make FT faster. For anyone who’s trained models in Pytorch, you’ll know to use ‘autograd’. It’s not very computationally efficient for repeatingn operations like attention. So, in the code above, you’ll see handwritten GPU kernels and manual derivation to be calculated on the fly.

Fine Tuning
Now we can train and FT a small LLM. Unsloth has a bunch of small models. One is Microsoft’s Phi-3-mini-4k-instruct. Its max sequence length (context window) is 2048, compared to Claude 3.5 Sonnet at 200k.
- Step 1 - Load the model and tokenizer
- Step 2 - Add LoRA adapter
- Step 3 - Train (using the trl library built on HF transformers)
- Using the A100, it took 5 minutes to train 3 epochs, 189 total steps
- Step 4 - Test the FT’d model
Links
I can’t take any credit for this notebook! It was built by the brilliant “Tech with Tim” (https://www.youtube.com/@TechWithTim), with enough bones that allowed me to spend (too much) time researching into a rabbit hole. Here’s the notebook, too.
The entire tutorial - all the AI stuff - was easy to follow. Actually, it was all the errors I encountered converting the Unsloth LoRA into a GGUF format that could be read by Llama-cpp. That was more or less the problematic part, as Unsloth’s quantization failed. That’s too bad since I was going to run it locally on my machine. But I think there are manual ways of conversion around this.