Federated Learning and GANs - The Lost Chapter

Overview
The below is a chapter that I ended up not publishing in my final PhD dissertation because the nature of the research - proposed during my proposal phase a year before - was too complex. The thrust of my dissertation research focused on GANs writ-large and multimodality. But adding on the additional task of Federated Learning (FL) and a little touch of Reinforcement Learning (RL) would have made it blow up into a second dissertation! However, I wanted to keep a record of it here because I still think there's strong merit in the idea of marrying FL with GANs, especially due to the rise of FL as a training and inference strategy for LLMs.
Research Question and Motivation
“What synchronization strategies can be applied to a Federated VTF-GAN, in order to preserve multimodal generative capacity while promoting convergence across non-IID data?"
Consider a scenario where telemedicine patients wish to use VTF-GAN on their mobile devices.
Since the facial data used for the translation task contains protected features of gender, race, and age, such data cannot be shared on a central server to train the global VTF-GAN model. Further, since mobile devices have limited network connectivity and typically contain non-IID data, updating all local models simultaneously, in parallel, is not practical.

For these reasons, Federated Learning (FL) is an attractive machine learning option for when it comes to protecting sensitive health data in the form of human faces for the VTF-GAN translation task. In FL, locally trained models housed on distributed mobile devices communicate with a central server that aggregates the local weights and updates the global model, all without transmitting local data.
Gold Standard Traditional FL
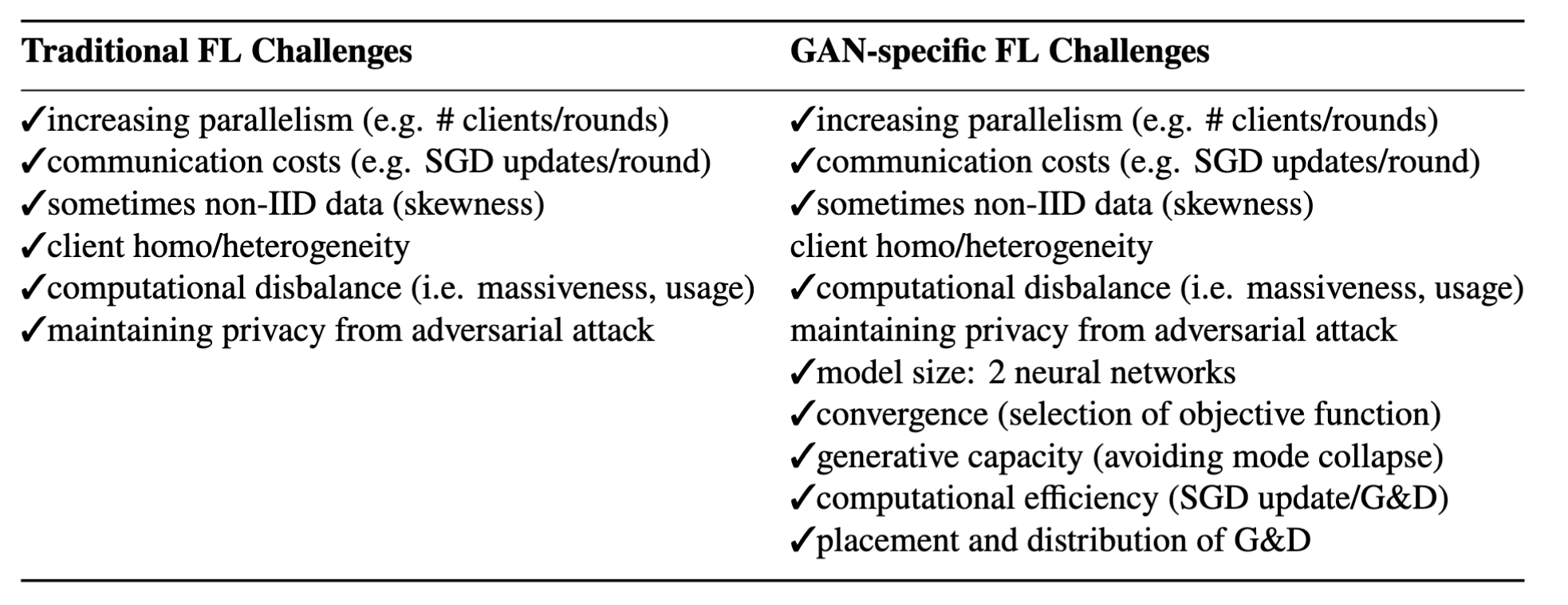
Traditional FL challenges include exchanging weights in a computationally efficient manner between local and global models, so that the global model may converge to a target accuracy rapidly in a minimal number of communication rounds. The gold-standard framework for FL is FedAvg, a method where at each connection round, a random subset of local clients is selected by the central server.
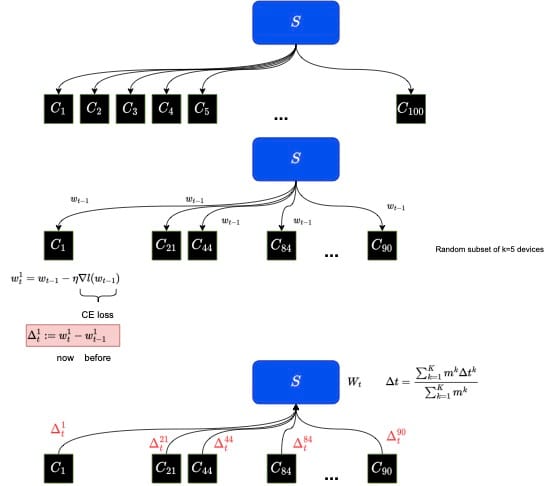
Each of the selected devices, \(k \in [K]\), then download global weights \(w_{t-1}\) from the central server, and perform local training:
$$w_t^k = w_{t-1} - \eta\nabla l(w_{t-1})$$
Each device reports back their weight differences of current minus the last round of training updates:
$$\Delta_t^k := w_t^k - w_{t-1}^k$$
The server then computes FedAvg to update the global model, where \(m^k\) is the number of batches of local data:
$$\Delta t = \frac{\sum\limits_{k=1}^K m^k \Delta t^k} {\sum\limits_{k=1}^K m^k}$$
Although this approach has been validated on IID datasets, FedAvg can converge extremely slowly is non-IID data, where each device contains a skewed distribution. The problems are magnified when data is distributed across a high number of devices.
Tests show that using FedAvg on IID using a two-layer CNN for MNIST classification leads to a 99% target accuracy convergence in 47 rounds.
But when data is non-IID, the number of training rounds extends to 163. Multiple works have been evaluated to improve training against non-IID data, to include alternative takes on FedAvg, relaxing constraints for local updates, investigating different optimization methods, or improving the selection of random devices.
SOTA with Federated GANs
These problems grow more computationally expensive and algorithmically complex when GANs are introduced, as opposed to existing studies using CNNs. In the past two years, the field of federated GANs has attracted more interest, where the SOTA are MD-GAN and FL-GAN.
With FL-GAN, both generator G and discriminator D are deployed to each client as well as the server. Each client trains their local GAN using SGD based on their local data which is assumed IID. The parameters for the local G and D are then uploaded to the server, which aggregates all parameters and distributes them across the clients.
Each GAN's original weights are replaced and undergoes local training again.
The aggregation is:
$$w_*^{t+1} = \frac{1}{n}\sum_i^n w_i^t$$
where \(w_*^{t+1}\) is the (new) aggregated parameters, \(w_i^t\) are parameters for the local client GAN, at round t for all client nodes n.
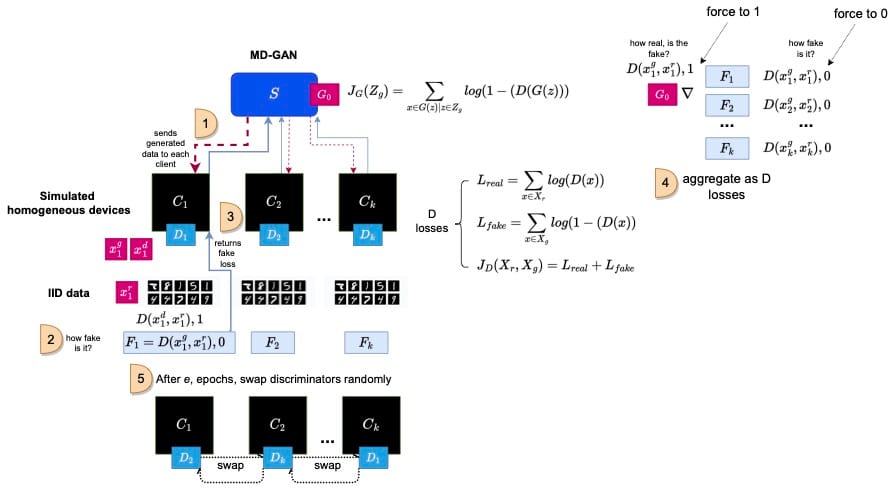
With MD-GAN, the architecture differs from FL-GAN since only G is stored on the server and only the D is deployed across the clients.
After the server sends generated data to each client, the D's predict the real and fake results, sending them back up to the server. The server aggregates all the D results in a method similar to FL-GAN and updates the global G parameters. The D's then share parameters across all clients:
$$w_*^{t+1} = w_i^t + \sum_j^n a_{ij} (w_j^t - w_i^t)$$
where \(w_i^t\) is the local discriminator's parameters, \(w_j^t\) and \(w_i^t\) are two neighboring client nodes, and \(a_{ij} \in [0,1]\) is the averaging weights. After a specified number of epochs, D's are randomly swapped between devices. MD-GAN also assumes IID data.
Challenges federating VTF-GAN
First, most FL GAN works evaluate vanilla GAN or CycleGAN, where the training objectives minimize Jenson-Shannon (JS) divergence:
$$JSD(p_{data}||p_{g})$$
between real \(p_{data}\) and fake \(p_{g}\) data distributions.
With VTF-GAN (and many other GANs), our training objective between G and D do not follow the objective of vanilla GAN.
For example, in vanilla GAN, convergence can be guaranteed when D reaches optimality meaning that \(D^*(x) = \frac{1}{2}\), allowing the entire JSD term to reach zero when \(p_{data} = p_g\). This is further guaranteed when \(p_{data}\) and \(p_g\) overlap in distribution.
VTF-GAN is based on a relativistic objective that we have yet to evaluate in terms of manifold properties. Further, its losses (i.e. perceptual loss, structural loss, temperature loss, Fourier loss) further complicate the objective. How this will effect distributed learning, especially on non-IID datasets is unknown. As a result, the choice of our objective may introduce challenges not yet encountered in the classic vanilla GAN scenario.
Next, a variety of synchronization strategies exist where no universal approach for GAN seems apparent.
Frameworks can focus on the weighting schema, the distribution of G vice D, the partitioning and orchestration of weights, or all of the above. But experts note that the nature of "how non-IID" the data is, determines the success of many strategies.
VTF-GAN data will be non-IID.
Given the paired data setting, \({x,y)}\), the feature space X are the visible images and Y, normally referred to as the label space, is the paired thermal image. Further, VTF-GAN data is more complex than MNIST. VTF-GAN data is feature skewed meaning the domain across all devices are human faces, but will vary in terms of demographic properties, geometry (i.e. pose, angle) and lighting conditions.
Federated GAN Training Options
When tested on GANs, FedAvg leads to longer training times. Further, if the global GAN is triggered to update local weights after a specific number of rounds, it can cause the local GAN to slide out of equilibrium.
As a result, a myriad of strategies have emerged to promote stable training of federated GANs while preserving generative capacity and keeping computational costs low.
One example is to score weights using Maximum Mean Discrepancy (MMD), which assigns different weights local GANs, as opposed to uniform weights under the FedAvg model.
Another is adaptive compression where each client estimates local bandwidth and determines the compression rate, compresses the generated data, and mixes it with local real data.
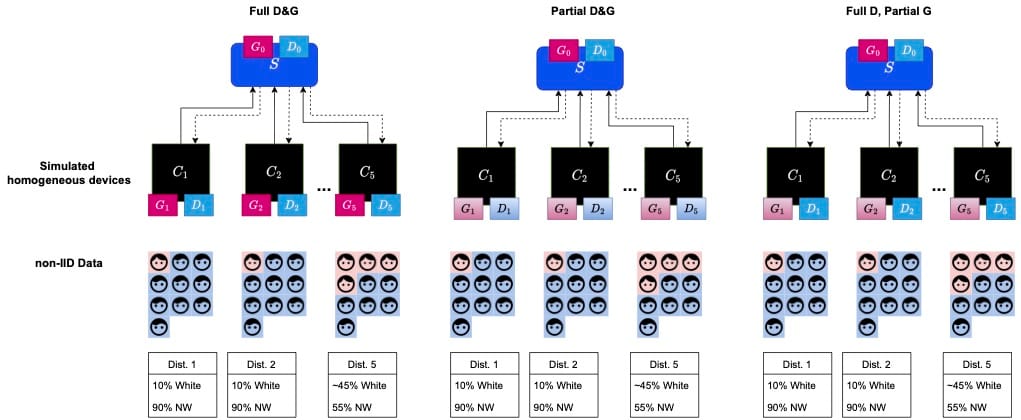
In contrast, others recommend to tackle the design strategy whereby local training should only involve the G and D (or just the G), but never the D only, since the discriminative capacity exceeds the G in most GAN conditions (e.g. D has an easier job than G in the start).
Still other strategies involve personalized federated learning. One example is FedRecon which gets away from maintaining local weights and instead focuses on reconstruction of local parameters, only when needed.
Similarly, another method relaxes the constraint that the client must have the same parameters as the global GAN. Instead, parameters are updated locally by training on a combination of local data and random, aggregated data sampled from the server.
Another approach called FAVOR, uses a Reinforcement Learning (RL) agent with FedAvg on non-IID data but has only been applied to CNNs. The agent is designed to intelligently select a subset of devices that are identified based on similar data distributions which is implicitly tied to their weights. Using a Deep Q-Network (DQN), the agent computes an action-value function:
$$Q(s_t,a; \theta_t)$$
defined by a state \(s_t\), action a, and reward \(r_t\).
It maintains a list of states for the global and local models per round. It selects a subset of top-K devices among all available devices to train, based on maximizing a reward function which is a function of test accuracy on the hold-out set.
Opportunities for Federated Learning with VTF-GAN
Our approach is called Federated Learning Thermal GAN (FeatherGAN)which extends VTF-GAN to function in a FL setting on IID and non-IID data distributions.
The mode is a silo-based system where the devices are simulated as discrete hospital servers that do not communicate with another, but download a trained FeatherGAN model directly from a central server.
Stage 1 - Experimental Setup
The dataset will be the Devcom dataset, previously used in all VTF-GAN training. Compared to existing VT facial datasets, Devcom is the most diverse ethnically, where upon a manual review of the data, I found 75% to be White and 25% of subjects to be Non-White. Further, the dataset is predominantly women compared to men. This offers the ability to spread the data in a non-IID manner across devices.
Many experiments simulate local devices per thread, and run anywhere from 100 to several thousand. A minimum of five clients per test bed should be deployed to create a simulation environment.
This phase explores the feasibility of applying any FL strategy whatsoever in VTF-GAN, which will have to be reduced in dimensionality (possibly PCA on the G or quantization), using the basic assumption of IID data. I envision significant contributions arising from this phase, alone.
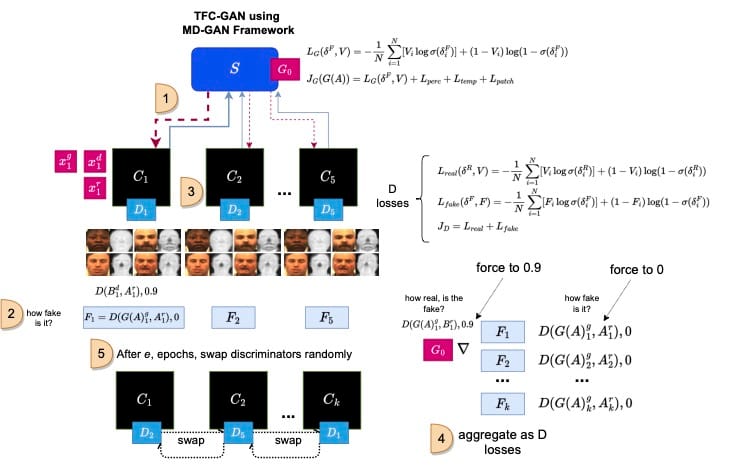
FeatherGAN on non-IID Data
Stage 2 builds on the approach by distributing the Devcom data in a non-IID fashion and will explore alternative FedAvg weighting schemes like MMD in addition to various collocations of D and G across clients and the server. Non-IID data simulations include, given the dominant "class" is white ethnicity:
\(k_1\) contains \(p=0.10\) (10% data White, 90% non-White)
\(k_2\) contains \(p=0.10\)
\(k_3\) contains \(p=0.20\)
\(k_4\) contains \(p=0.15\)
\(k_5\) contains \(p=0.45\)
References
- McMahan, Brendan, et al. (2017). Communication-efficient learning of deep networks from decentralized data. In Artificial intelligence and statistics (pp. 1273-1282). PMLR.
- Kairouz, Peter, et al. (2021). Advances and open problems in federated learning. Foundations and Trends in Machine Learning, 14(1-2), 1-210. Now Publishers, Inc.
- Fan, Chenyou; Liu, Ping. (2020). Federated generative adversarial learning. In Chinese Conference on Pattern Recognition and Computer Vision (PRCV) (pp. 3-15). Springer.
- Hardy, Corentin, et al. (2019). Md-gan: Multi-discriminator generative adversarial networks for distributed datasets. In 2019 IEEE International Parallel and Distributed Processing Symposium (IPDPS) (pp. 866-877). IEEE.
- Li, Wei, et al. (2022). IFL-GAN: Improved Federated Learning Generative Adversarial Network With Maximum Mean Discrepancy Model Aggregation. IEEE Transactions on Neural Networks and Learning Systems. IEEE.
- Tabassum, Aliya, et al. (2022). FEDGAN-IDS: Privacy-preserving IDS using GAN and Federated Learning. Computer Communications, 192, 299-310. Elsevier.
- Xin, Bangzhou, et al. (2020). Private fl-gan: Differential privacy synthetic data generation based on federated learning. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 2927-2931). IEEE.
- Xin, Bangzhou, et al. (2022). Federated synthetic data generation with differential privacy. Neurocomputing, 468, 1-10. Elsevier.
- Nguyen, Dinh C, et al. (2021). Federated learning for COVID-19 detection with generative adversarial networks in edge cloud computing. IEEE Internet of Things Journal. IEEE.
- Zhang, Yikai, et al. (2021). Training federated gans with theoretical guarantees: A universal aggregation approach. arXiv preprint arXiv:2102.04655.
- Cao, Xingjian, et al. (2022). PerFED-GAN: Personalized Federated Learning via Generative Adversarial Networks. IEEE Internet of Things Journal. IEEE.
- Behera, Monik Raj, et al. (2022). FedSyn: Synthetic Data Generation using Federated Learning. arXiv preprint arXiv:2203.05931.
- Amalan, Akash, et al. (2022). MULTI-FLGANs: Multi-Distributed Adversarial Networks for Non-IID distribution. arXiv preprint arXiv:2206.12178.
- Zhang, Xiongtao, et al. (2021). DANCE: Distributed Generative Adversarial Networks with Communication Compression. ACM Transactions on Internet Technology (TOIT), 22(2), 1-32. ACM New York, NY.
- Goodfellow, Ian, et al. (2014). Generative adversarial nets. In Advances in neural information processing systems (pp. 2672-2680).
- Zhu, Jun-Yan, et al. (2017). Toward multimodal image-to-image translation. In NeurIPS (pp. 465-476).
- Zhou, Kaiyang, et al. (2019). Learning Generalisable Omni-Scale Representations for Person Re-Identification. arXiv preprint arXiv:1910.06827.