Multimodal Representations

Dear Reader: I came across a paper I had started drafting in 2019 on Multimodal Machine Learning - at the time a very new and fascinating field that I was considering to apply towards my Ph.D. Lo and behold, here we are nearly six years later and my dissertation was about Multimodal AI. Anyway, this work below is dated but I still think it offers some value as a historic literature review into how the world was before "ChatGPT". Enjoy!
Representation learning is “learning representations of the data that make it easier to extract useful information when building classifiers or other predictors.
In the example of image data, instead of selecting and hand-crafting features manually that we may believe are relevant about the data such as computing pixel intensity, shape, and textures, we can use models such as convolutional neural networks (CNNs). These algorithms learn meaningful data representations through successive, abstract, deeper layers that are compositions of non-linear transformations. Earlier layers in the network (“bottom” layers) capture details of the input modality like corners, edges, and textures of the input image. Subsequent layers deeper into the network (“top” layers) capture more abstract information about the input image that have greater variety and are less specific to the objects in question.

These higher layers have greater invariance to changes in the data at the first layer. Zeiler notes that small transformations in the input data have dramatic effects in the first layer of activations (feature map), but less so in the higher, later layers of the network where the representations are invariant to translations and scalings. As a result, there is a hierarchical (from bottom to top) nature of features in the CNN.
The goal is to have invariant, abstract features, that despite local changes of features in the data, the representation itself will not change and therefore preserve information.
Unlike unimodal representations (one data type), multimodal representation focuses on how to combine data from multiple, heterogeneous sources (e.g. image and text), handling different levels of noise across varying modalities, and how to deal with missing data. Joint representations combine unimodal representations together into one space. The simplest example is concatenating two representations into one, for example one single matrix of image and text, together into one large vector. Pang et al learned multimodal feature representations for video, sound, and text in order to understand perceived emotions from social media and other user-generated content. Using Restricted Boltzmann Machines (RBMs), a graphical network that can be stacked together as a Deep Boltzmann Machine, they learned three representations separately and combined them into a single joint representation, the final set of distributions across modalities.
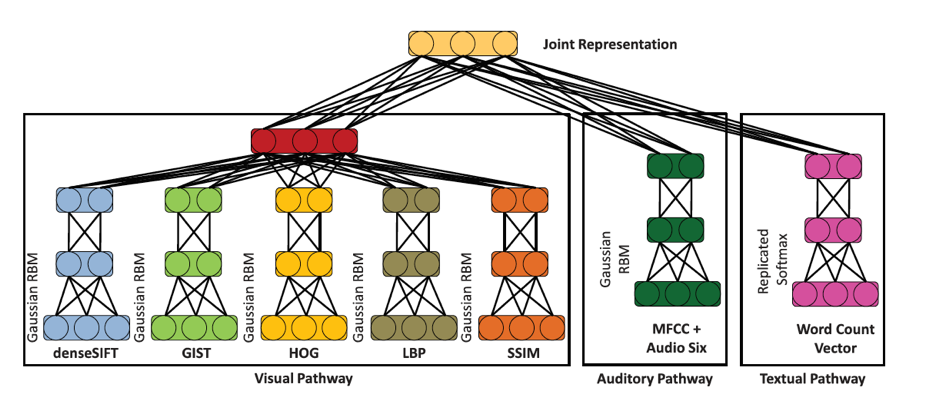
Translation
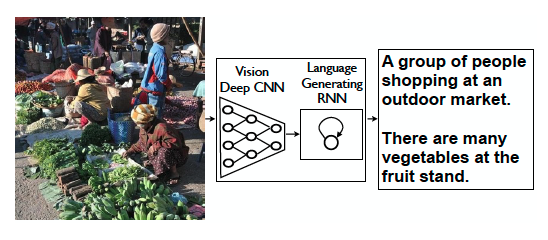
Translation is the process of changing one modality (like an image) into another (like text).
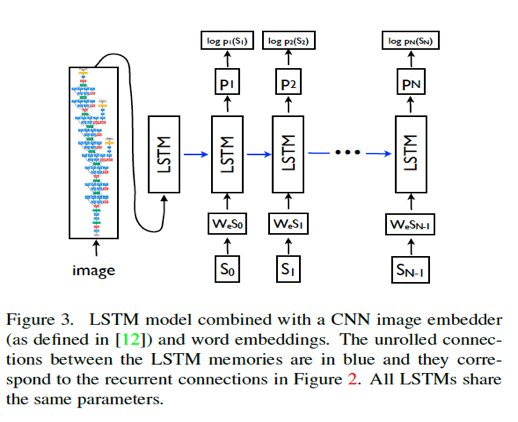
A popular example is generative translation which automatically constructs a model capable of producing a translation, given only an unimodal data source - such as voice-to-text streaming using the audio modality to generate a sequence of text. Another example of translation is visual scene description or image and video captioning. Vinyals et al developed a translation model that automatically generates English sentences that describe the contents of an image.
This requires describing the objects in the image, the activities depicted, and how they relate to each other. Using an encoder-decoder architecture, the CNN encodes the image into an unimodal representation that is used as the hidden state of a decoder recurrent neural network (RNN) with Long Short-Term Memory Units (LSTMs) that generate the target sentence. The model was trained on the MSCOCO dataset where each image is labeled with 5 sentences.
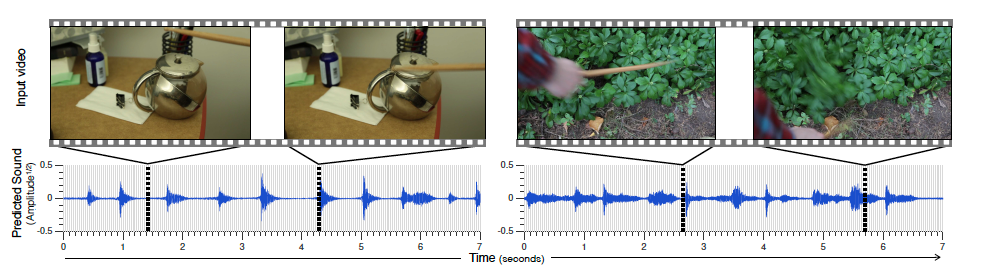
Another example of translation is by Owens et al who developed a regression model to map a sequence of video frames to a sequence of audio features, also using a CNN and RNN like Vinyals. Their RNN with LSTM units takes the image features for each video frame generated by the CNN as inputs. Both the RNN and CNN are trained jointly using stochastic gradient descent. Their model predicts what sound an object makes when struck by a drumstick. It synthesizes sound from silent videos comprising of objects being hit or scratched by a drumstick.
Alignment
Alignment addresses the challenge of identifying direct relationships between sub-elements from two or more different modalities.
Although the model in Bahdanau et al is text, the alignment model they develop can be considered as sub-elements (e.g. two different foreign languages) from one text modality. They demonstrate language translation from English to French using an alignment model called “soft alignment” that matches the inputs of English words to outputs of French words using a single trained bidirectional RNN that reads a sentence and outputs the correct translation.
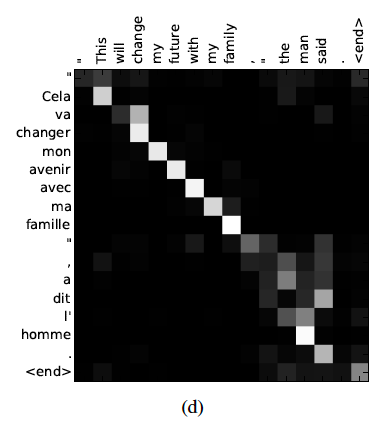
This differs from previous traditional approaches of using an encoder-decoder architecture. In the traditional approach, encoder-decoders consist of two separate neural networks. The encoder (e.g. RNN) encodes a source sentence (English) into a fixed-length vector and the decoder (e.g. RNN) translates it into the target language (French). Both networks are jointly trained using language (e.g. English-French) pairs. The difference with Bahdanau is their network does not try to encode an entire input sentence into a fixed-length vector, but rather transforms the input sentence into a sequence of vectors and chooses a subset of the vectors based on the context of surrounding words in order to predict the translated output word.
As a result, longer sentences that do not meet the fixed length can be translated through this approach of jointly learning to align and translate simultaneously. The figure above provides a visual illustration of the alignment model showing the annotation weights visualized in the pixels of the figure. This particular visualization depicts what Bahdanau points out as the value of “soft alignment” versus “hard alignment”, where the phrase [the man] (x-axis source English sentence) was translated into [l’ homme] (y-axis translated French sentence). Hard alignment would directly align [the], regardless of the gender of the noun following (in this case [man]) with [l’] every single time. Other options based on the following noun could be [le], [la], or [les]. Soft alignment allowed the model to look at both [the] and the following word [man] in order to correctly translate [the] into [l’].

Karpathy et al developed an approach to model alignment of regions of images with explicit references in sentences, by taking fragments of image and text and embedding both into a common representational space. The model associates image fragments of objects and scenery with fragments in sentences which are the typed dependence tree relations mapped from the Stanford NLP Parser. The dependency is an encoding of the sentence’s entity, attributes (adjectives), and interactions (activities among entities like running).
Fusion
Fusion is the process of joining information from two or more modalities to perform a prediction.
It combines the multimodal representations for a specific task, like classification or regression, and can be model-agnostic in its implementation, meaning models not originally designed for multimodal data are used, or fusion can be accomplished using specifically designed multimodal algorithms such as the MultiModal Deep Boltzmann Machine (MM-DBM) used by Suk et al for Alzheimer’s Disease prediction.
Liu et al apply multiple kernel learning as the fusion technique to predict Alzheimer’s Disease and Mild Cognitive Impairment (MCI) Diagnosis using two modalities – cerebrospinal fluid (CSF) biomarkers and gray matter density values in magnetic resonance imaging (MRI). The data comes from 120 subjects, randomly drawn from the Alzheimer Disease Neuroimaging Initiative (ADNI) database where the MRI data is divided into three types of information - left hemisphere hippocampus shape (HIPL), right hemisphere hippocampus shape (HIPR), and grey matter volumes within Regions of Interest (ROI).
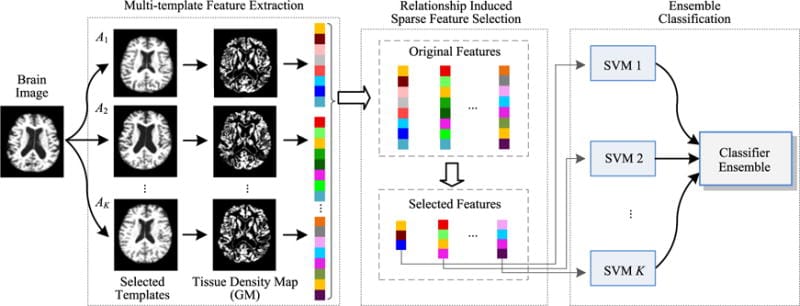
Data is concatenated into a high dimensional vector before training a classifier, a method called “early fusion”. Their approach uses Support Vector Machines (SVMs) that can be used for classification tasks by casting non-linear low-dimensional features into a higher dimensional space so that a linear decision boundary can separate classes. This is achieved through a mapping function called the “kernel trick” to find the optimal kernel weights for the SVM. Instead of finding the kernel weights which can be computationally intensive, Liu et al explicitly compute the mapping function needed across all kernels, for each of the four modalities to obtain an approximate embedding. This embedding is used to select the most discriminative features to improve classification accuracy.
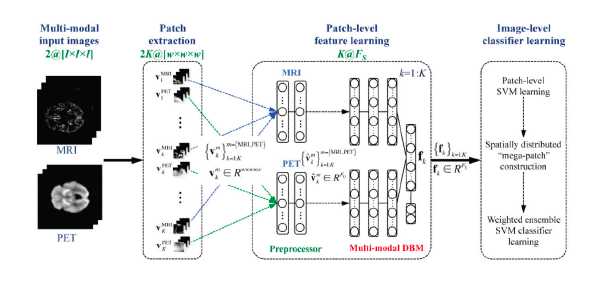
Suk et al introduce a fusion technique that differs from Liu through feature learning via a deep learning graphical model called a Deep Boltzmann Machine (DBM), a network that stacks individual Restricted Boltzmann Machines. Suk uses the DBM to discover a joint, hierarchical feature representations from “voxel values” extracted from pairs of Magnetic Resonance Imaging (MRI) and Positron Emission Tomography (PET) image patches, as opposed to using hand-crafted features like Liu. Suk adopted a MultiModal DBM (MM-DBM) similar to Srivastava et alc to combine the pairs of tissue densities of an MRI patch and voxel intensities of a PET patch. Once the MM-DBM learned the feature representation of the pair of data, a binary image classifier was trained using the representations via a linear SVM, and experiments conducted to predict Mild Cognitive Impairment (MCI) and Alzheimer’s Disease.
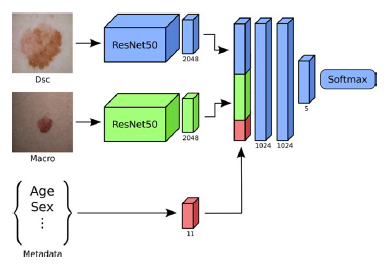
MMML can be applied to different sub-modalities. A study on automated skin lesion diagnosis similarly combined different sub-modalities based on the intuition that dermatologists examine multiple images and data to arrive at a diagnosis, not only one image. Yap et al combined feature representations learned from a CNN (ResNet50) for each of the image types (macroscopic and dermatoscopic) combined with a metadata vector that described information about the patient. The multimodal network is used to predict whether the image is one of five diseases - naevus, melanoma, basal cell carcinoma, squamous cell carcinoma, or pigmented benign keratoses.
Co-Learning
Co-learning helps a model by exploiting information from a resource-rich modality for a resource-poor modality and is usually implemented during training and not testing.
Transfer learning which is a common approach in deep learning, uses a clean and large volume of data, such as the ImageNet dataset containing over 1.2 million categorized natural images of 256 x 256 dimension of 1000+ classes.

Transfer learning is an approach when seeking to train a model with much smaller and poorly annotated or untrustworthy set of labels.
Researchers at the National Institute of Health (NIH) developed a MMML called Text-Image Embedding network (TieNet) for extracting the distinctive image and text representations from Chest X-rays and reports.
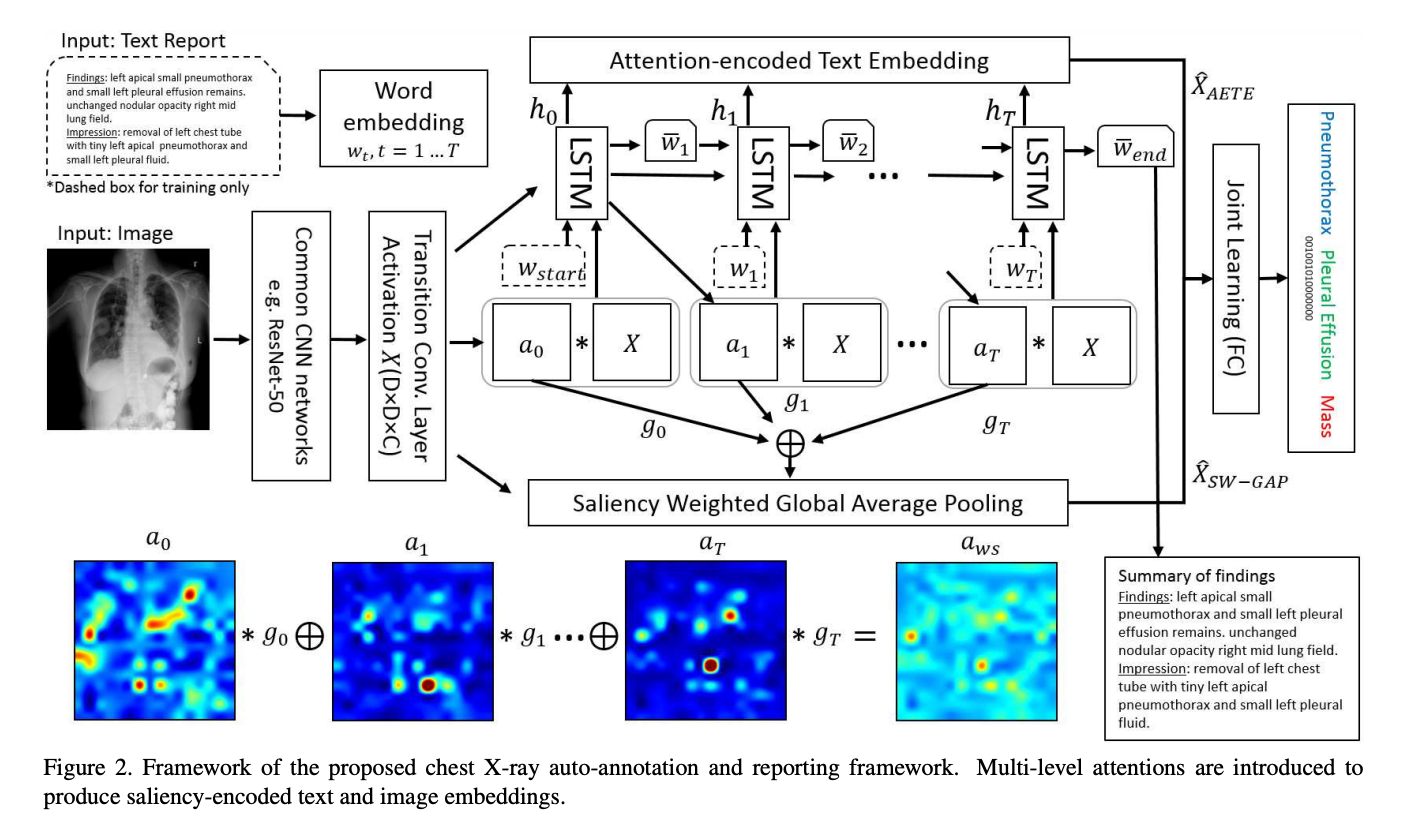
TieNet can be used to simulate a clinical process of assigning disease classifications to Chest X-ray images and generating preliminary report text. Wang et al train a CNN-RNN architecture that uses two modalities – the X-ray image and its corresponding sequence of encoded words (e.g. the report text). They use attention models integrated into the network to learn an encoding of attention-based text embeddings and meaningful image features, or saliency weights.
Similar to many of the methods previously introduced, they jointly learn the feature representation by concatenating both the attention text and image encodings together into a large vector, which is then fed into a final fully connected layer to output the multi-label disease classification. Wang et al used the ResNet-50 CNN pre-trained on ImageNet and kept the convolutional and fully connected layers fixed from layers Conv1 to Res5c, using the CNN as a deep image extractor to obtain meaningful image feature representations of the X-ray images.
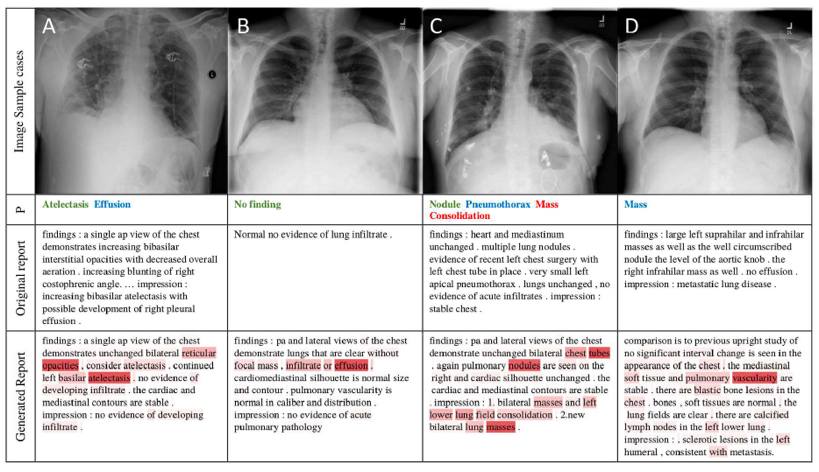
In a discussion by Hoo-Chang et al, they point out that for the medical domain, because collecting and annotating large numbers of medical images is challenging, transfer learning through the use of “mainstream” CNNs like AlexNet, provide tens of millions of free parameters to train on.
Further, the use of deep CNNs with architectures of 8 to 22 layers can be useful for medical computer vision, or “computer-aided detection” problems (e.g. thoraco-abdominal lymph node (LN) detection and interstitial lung disease (ILD) classification), when available medical training is limited. Prior to Hoo-Chang’s study in 2016, they noted that previous CNN models were up to 5 orders of magnitude smaller. In their experiments, they also conclude that transfer learning using natural image datasets from ImageNet has benefited medical image domain classification.
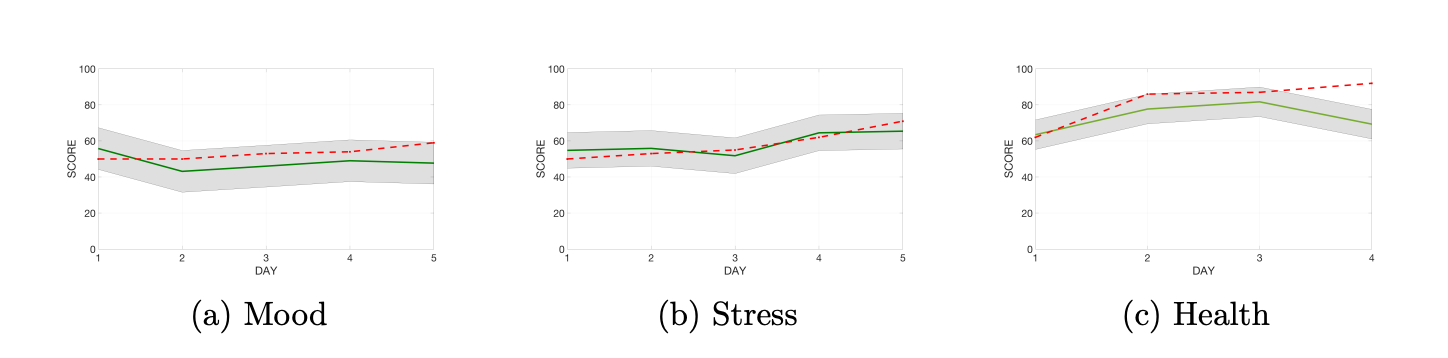
Researchers at MIT implemented an approach called Multi-Tasking Learning (MTL) to develop a personalized model to predict an individual’s wellness and mood. Jacques et al combine data from the SNAPSHOT: Sleep, Networks, Affect, Performance, Stress, and Health using Objective Techniques study – a dataset measuring human well-being including stress, health, energy, alertness, and happiness. The data spanned 2000 days of physiological, survey, and smartphone data including GPS coordinates, skin conductance, skin temperature, accelerometer, steps, and stillness.
Jacques et al sought to use MTL in order to combat the key problem in existing mood prediction systems which is by attempting to predict every person’s mood using a single, universal model that fails to take into account the high level of personal variation in behavior and environment. Traditional machine learning models learn a single function over all the available data. But, MTL is a technique to address problems when the model needs to obtain predictions for multiple tasks (e.g. persons) simultaneously. MTL trains personalized neural networks for each individual (task), but all people benefit from shared feature extraction layers.
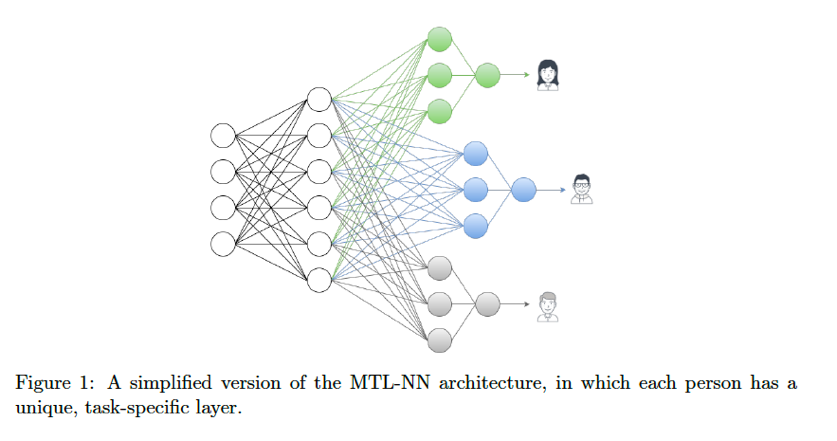
Similar to the research by Liu et al for Alzheimer’s Disease prediction, the well-being study adopted multiple kernel learning where each modality’s features are represented by its own kernel function. MTL provides benefits to mitigate overfitting by sharing information and noise across multiple tasks, focusing attention on specific representations, and introducing a machine learning concept called inductive bias. Inductive bias is introduced when one task learns the patterns of data another task prefers, causing the overall model to bias its learning towards different task hypotheses. The MTL learned a weighting over the 10 modalities of SNAPSHOT data for each task (e.g. person). The result was MTL leading to 13 – 22% lower average error compared to traditional models in predicting self-reported mood, stress, and health levels.
References
Zeiler, Matthew D., and Rob Fergus. "Visualizing and understanding convolutional networks." European conference on computer vision. Springer, Cham, 2014.
Y. Bengio, A. Courville, and P. Vincent, “Representation learning: A review and new perspectives,” TPAMI, 2013.
Lei Pang, Shiai Zhu, and Chong-Wah Ngo. Deep Multimodal Learning for Affective Analysis and Retrieval. IEEE Trans. on Multimedia, vol. 17, no. 11, pp. 2008-2020, 2015.
O. Vinyals, A. Toshev, S. Bengio, and D. Erhan, “Show and Tell: A Neural Image Caption Generator,” in ICML, 2014.
S. Venugopalan, H. Xu, J. Donahue, M. Rohrbach, R. Mooney, and K. Saenko, “Translating Videos to Natural Language Using Deep Recurrent Neural Networks,” NAACL, 2015.
Vinyals, Oriol, et al. "Show and tell: A neural image caption generator." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
Owens, Andrew, et al. "Visually indicated sounds." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.Bahdanau, Dzmitry,
Kyunghyun Cho, and Yoshua Bengio. "Neural machine translation by jointly learning to align and translate." arXiv preprint arXiv:1409.0473 (2014).
Karpathy, Andrej, Armand Joulin, and Li F. Fei-Fei. "Deep fragment embeddings for bidirectional image sentence mapping." Advances in neural information processing systems. 2014.https://www.cs.cmu.edu/~morency/MMML-Tutorial-ACL2017.pdf
Suk, Heung-Il, et al. "Hierarchical feature representation and multimodal fusion with deep learning for AD/MCI diagnosis." NeuroImage 101 (2014): 569-582.
Liu, F., Zhou, L., Shen, C. & Yin, J. (2014). Multiple kernel learning in the primal for multimodal Alzheimer's disease classification. IEEE Journal of Biomedical and Health Informatics, 18 (3), 984-990.
Suk, Heung-Il, et al. "Hierarchical feature representation and multimodal fusion with deep learning for AD/MCI diagnosis." NeuroImage 101 (2014): 569-582.
Zhang, Wenlu, et al. "Deep convolutional neural networks for multi-modality isointense infant brain image segmentation." NeuroImage 108 (2015): 214-224.
Yap, Jordan, William Yolland, and Philipp Tschandl. "Multimodal skin lesion classification using deep learning." Experimental dermatology 27.11 (2018): 1261-1267
Deng, Jia, et al. "Imagenet: A large-scale hierarchical image database." 2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009.Wang,
Xiaosong, et al. "Tienet: Text-image embedding network for common thorax disease classification and reporting in chest x-rays." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
https://arxiv.org/pdf/1512.03385.pdf
Shin, Hoo-Chang, et al. "Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning." IEEE transactions on medical imaging 35.5 (2016): 1285-1298.
Caruana, Rich. "Multitask learning." Machine learning 28.1 (1997): 41-75.
Jaques, Natasha, et al. "Predicting tomorrow’s mood, health, and stress level using personalized multitask learning and domain adaptation." IJCAI 2017 Workshop on Artificial Intelligence in Affective Computing. 2017.Sebastian Ruder (2017). An Overview of Multi-Task Learning in Deep Neural Networks. arXiv preprint arXiv:1706.05098.