The Good Ol' CNN
Dear Reader: I recently found a trove of papers I wrote back in 2019 and thought to post a few snippets!
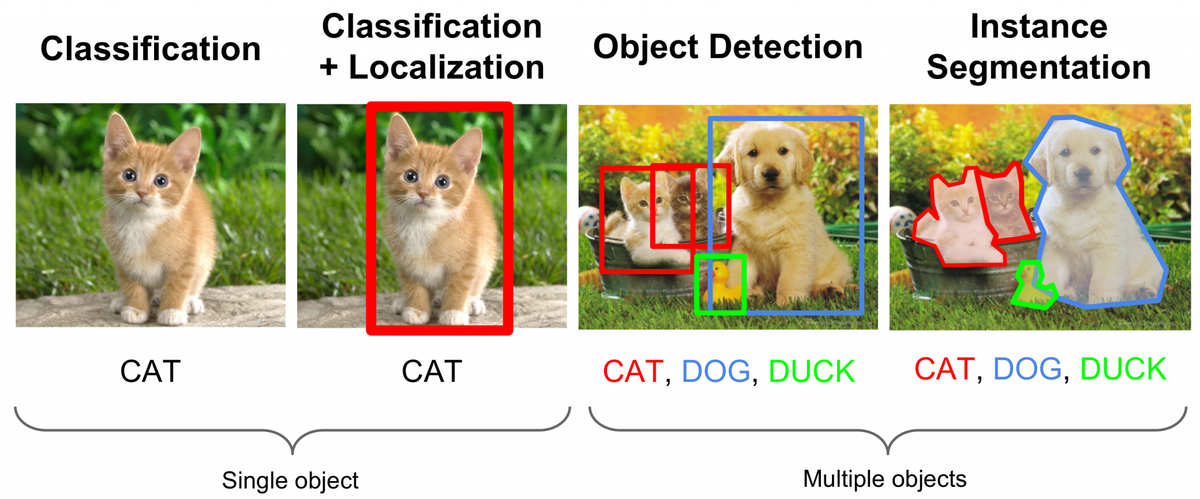
Convolutional Neural Networks (CNN) gained popularity in 2012 when AlexNet developed by Alexander Krizhevsky, Sustkever, and Hinton won that year’s ILSVRC (ImageNet Large-Scale Visual Recognition Challenge) classifying images on the ImageNet dataset with an error of 15.4% error, with the next best entry at 26.2% (Krizhevsky, 2012).
Since then, CNN’s have been increasingly used as the neural network architecture of choice for image recognition. Over several years, the accuracy of classifying 1000 categories on the ImageNet-2012 dataset have been steadily increasing. Where AlexNet won with a 15.4% error in 2012, subsequent neural networks have steadily increased accuracy such as the ResNet architecture with error of 3.57% in 2015 (Alom, 2018).
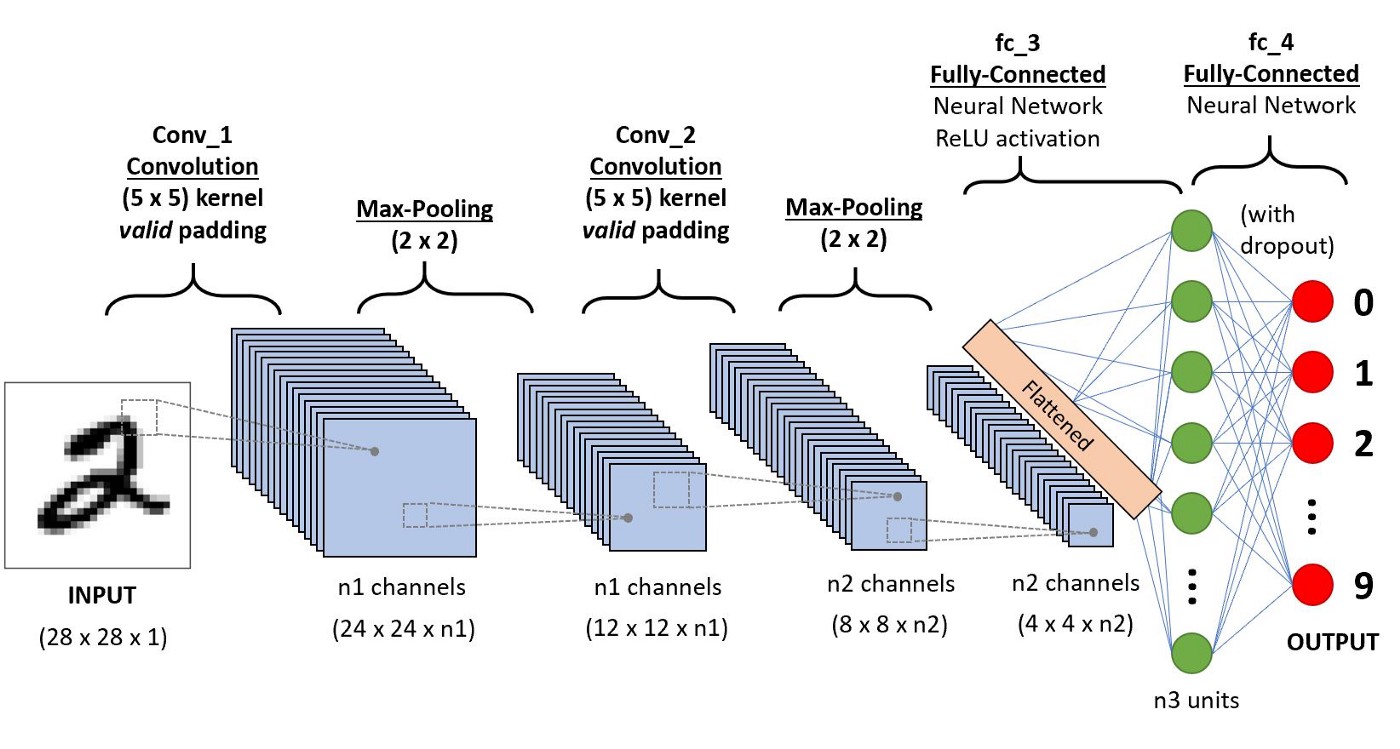
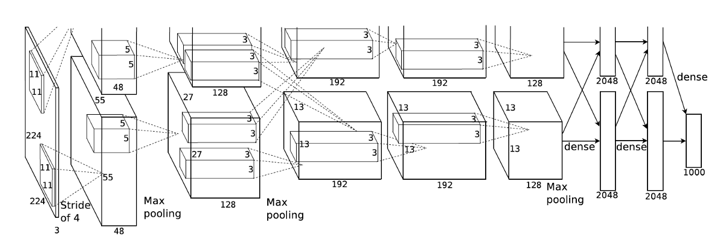
CNNs are able to process images and distill them into abstract representations across multiple layers of mathematical mapping operations referred to as convolutions. CNNs are composite functions, where the output of one layer is the input to the next. A typical CNN architecture for image classification consists of convolutional layers that perform convolutional filtering, non-linear (activations), pooling (downsampling) and sub-sampling, in addition to a set of fully connected layers and a softmax layer that outputs posterior probabilities for each class.
{kind=link}
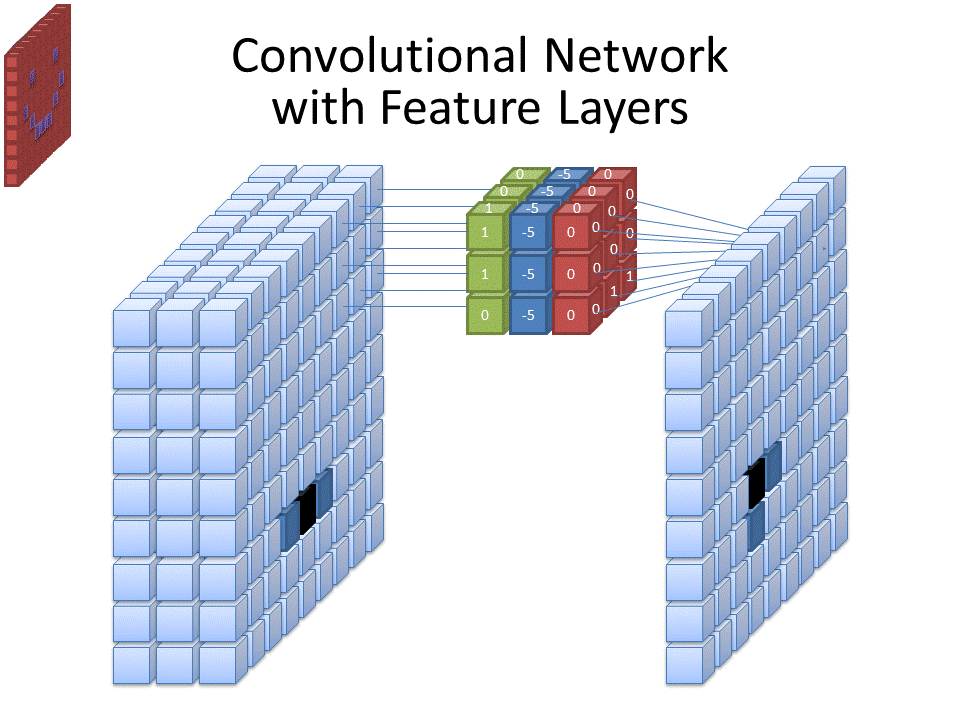
Different layers serve different purposes; convolutional layers apply spatial mappings between the outputs of one layer (called a feature map) with a receptive field (called a filter), pooling pllayers down-sample the feature maps, and fully connected layers connect all filters with one layer to all filters of the previous, each connection with its own weight.
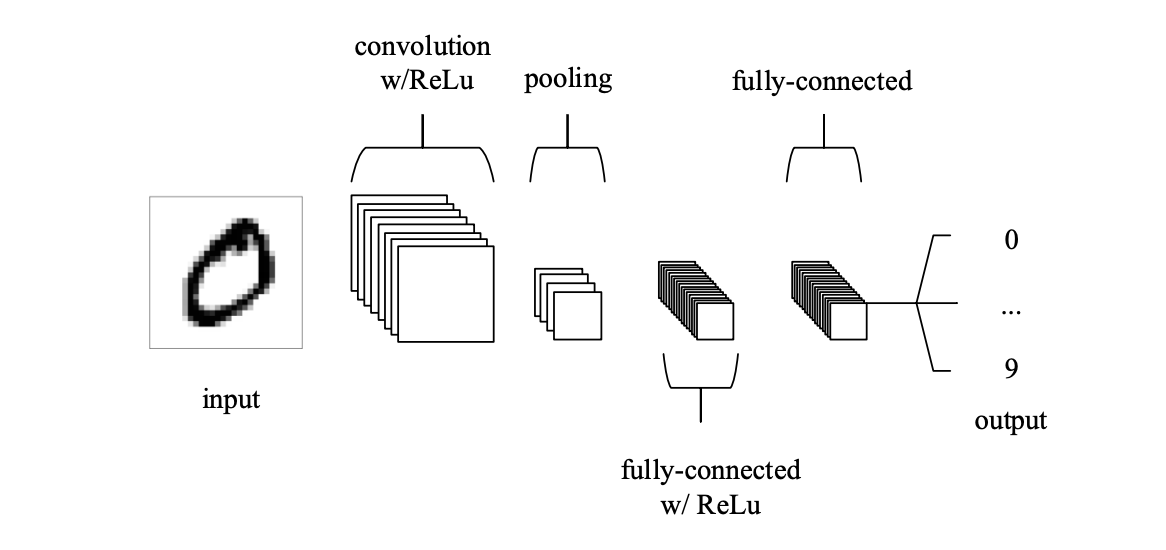
CNNs are trained to minimize a cost function such as log loss through forward propagation. This cost function calculates the error between the predicted and the true values for each image. The method of backward propagation minimizes the cost function using the chain rule, which takes the partial derivative of the cost function for a set of parameters (i.e. weights and biases) for each layer in the network. A process called gradient descent updates all the parameters simultaneously by adjusting them in the appropriate direction and magnitude to achieve the minimum error possible.