What is Multimodal AI, anyway?

Clearly, we see this MMAI everywhere nowadays. Enter a prompt in Midjourney and you now get an image. From VQGAN-CLIP who had released her code several years ago to offer the first example of using text prompts to generate images, to, RunwayGen that makes videos (like this 4-sec clip I just made) - MMAI is everywhere.
It seems the new term nowadays is "multimodal" which loosely means multiple data types. Given how the first word in the title of my doctoral dissertation is "Multimodal", I thought I might be qualified to help out!
Background
One of the key papers in multimodal machine learning (MMML) was written in 2017 and is a very approachable read: https://arxiv.org/pdf/1705.09406.pdf.

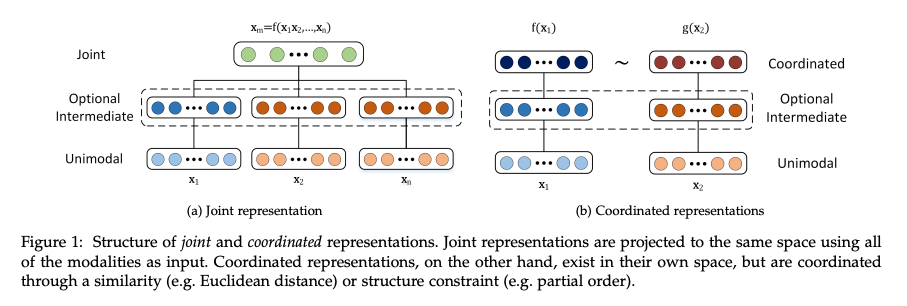
I've read this paper dozens of times and Baltrusaitis et al will break down for you one of the most key elements of MMML - representations of the data. You'll find this out for yourself when you read this paper, but in a nutshell, there are a few challenges that are unique when dealing with AI tasks that use multiple data types at once - for example, images and text, or sound and images. The challenges are 1) representation, 2) translation, 3) alignment, 4) fusion, and 5) co-learning. Given that the paper is seven years old, many of the challenges are easier to deal with now that we have neural networks and generative models that can represent the heterogenous data and their mappings in a latent space.
Now, to make it more concrete - when we're talking about Multimodal AI - we're talking about training either one or multiple neural networks as a single system using a fusion of different data types. We've already seen this in past through algorithms like image captioning from as far back as 2014 by Karpathy and Fei-Fei Li. Here, they pass a caption to a recurrent neural network (remember those, guys?) and the image to a convolutional neural network.
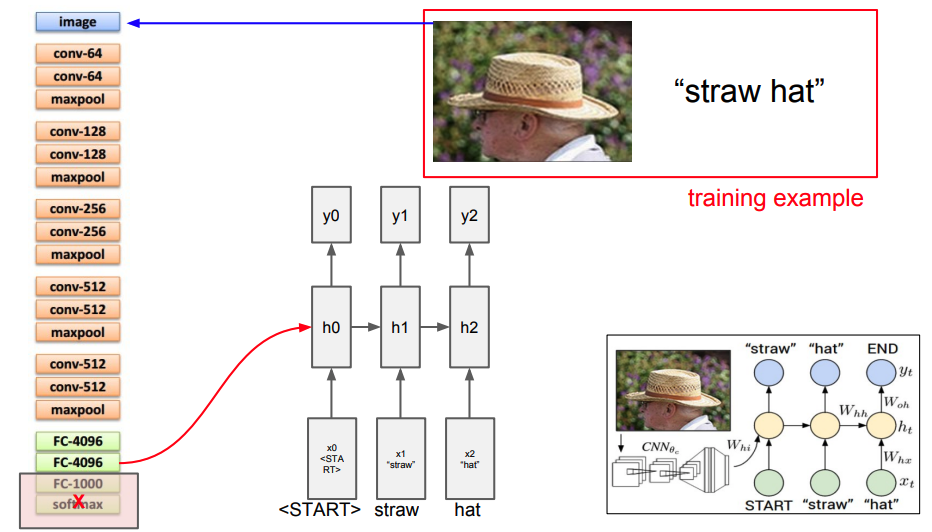
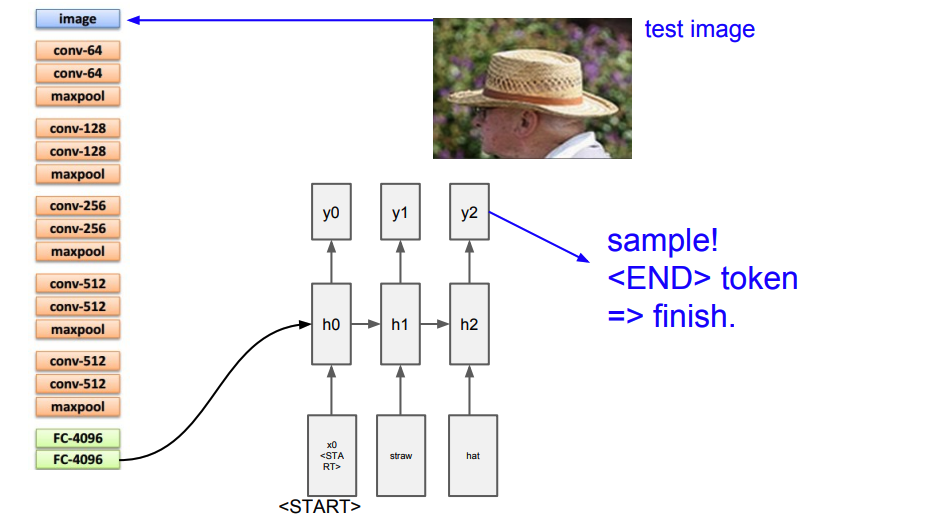
After training, only an image is passed at test time and a caption (or several) or generated.
How do you do it?
There are a variety of ways to deal with multimodal data. Sometimes it pertains to fusion strategies - early (close to the data) or late (at the decision level) fusion. Sometimes, it is a matter of the data representations as mentioned earlier. But, I think it's actually a combination of both. Note, it's not exactly "ensembling" which is typically done post-prediction with traditional ML models.
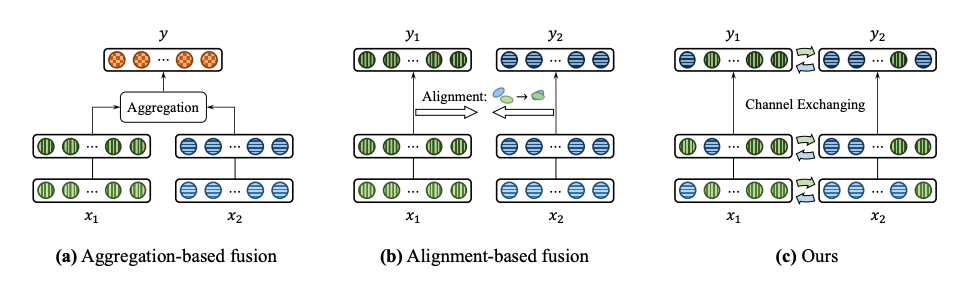
Nowadays, there is a ton of research about how to make a more robust multimodal fusion to capture discriminative information from each modality. A paper from ECCV 2018, CentralNet: a Multilayer Approach for Multimodal Fusion, offers a neural network architecture that takes a weighted sum of the layers that represent each modality. Next, this NeurIPS paper from 2020 by Yang, et al. Deep multimodal fusion by channel exchanging, offers a way to perform multimodal fusion within the data types.
In a more recent IEEE paper from 2023, Multimodal Fusion Transformer for Remote Sensing Image Classification, the authors demonstrate how to train a classifier on hyperspectral imagery and LIDAR.

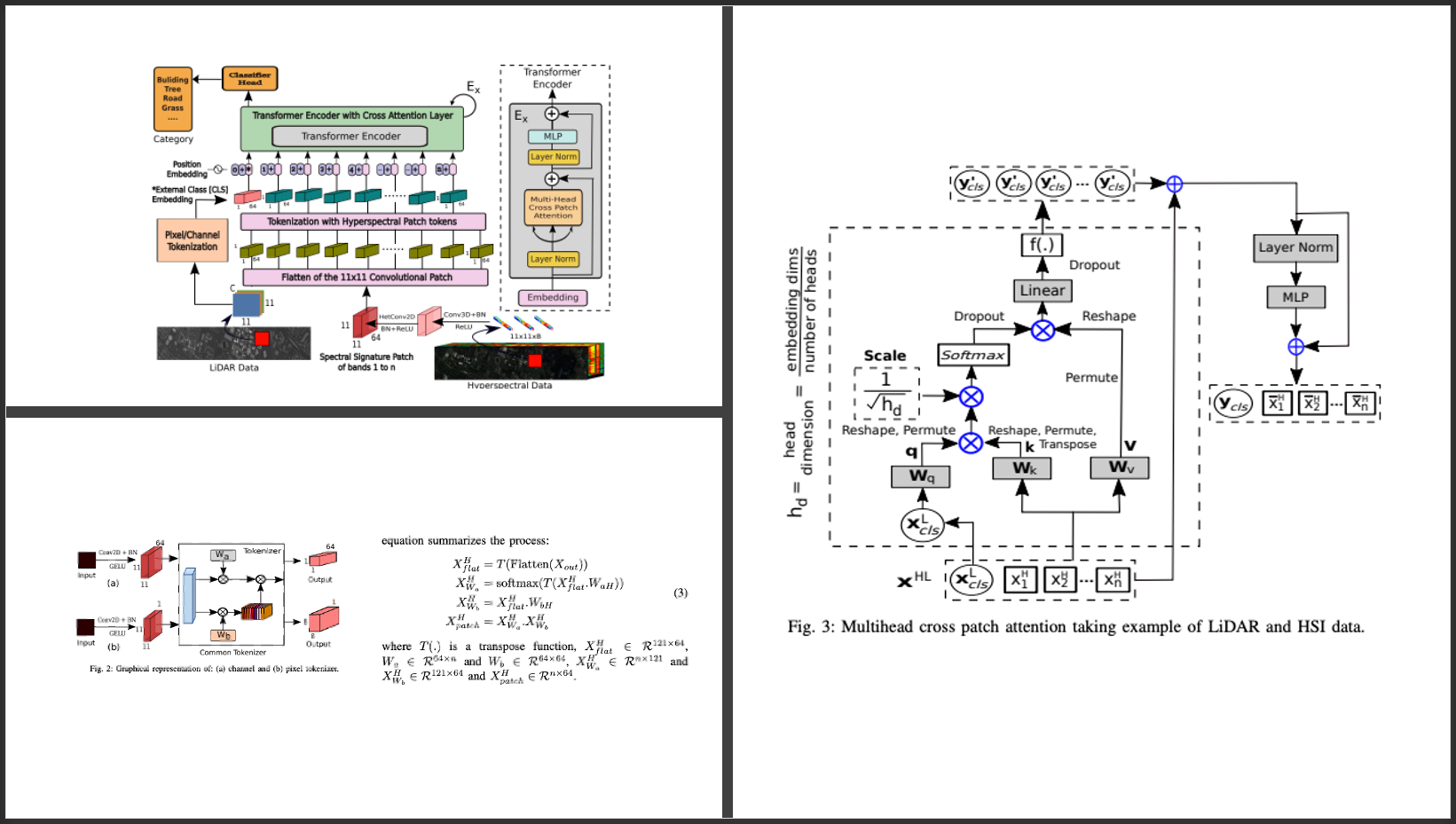
Yes, these diagrams look crazy complicated, but actually there are a few easy takeaways from this paper. First, it's my opinion that there is no standard method of MMAI and no "one ring to rule them all" - sorry. This paper exemplifies an excellent way to solve a very difficult MMAI problem of fusing LIDAR and HSL. Here, they used two learnable weights to extract key features from the inputs. They also do what I (and many other folks) have to do - which is manipulate the tensors (i.e. reshape, permute, transpose), in such a way as to pass through a multi-layer perceptron to arrive at a projected, common latent representation. I'm oversimplifying it, but their method is one way not the way.

Code, please?
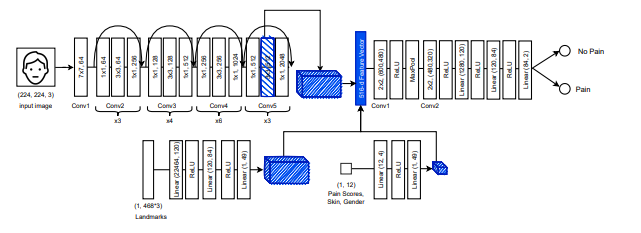
So, here's a straight-forward example that I used in a paper from 2021 at NeurIPS for the NIH Intelligent Sight and Sound chronic cancer pain classification task using multimodal data - facial images, 3D landmarks, and an inventory of psychological scores. The data structures are RGB image (e.g. [batch, 3, w, h]), 2D tensor of xyz values passed in per batch, and a plain 1D tensor of scores (e.g. [batch, K]).
This method is more or less, aggregation-based fusion, per the diagram below. The image is passed through a CNN that can accommodate any pre-trained backbone (i.e. ResNet50, VGG-16, etc.). Meanwhile, there are three other neural networks: 1) a MLP for the landmarks, 2) a MLP for the pain scores and demographics, and 3) a final CNN that takes the multimodal inputs with a softmax layer to learn the entire system via good ol' cross-entropy loss.
Here are some basic programming concepts in PyTorch. One of the key elements is to write a hook. This fetches the activation (or features) from any given layer.
def get_activation(name):
def hook(model, input, output):
activation[name] = output
return hook
Now, after having instantiated each of the models (the CNN, the MLP for landmarks, the MLP for pain/demographics, and the CNN for the overall multimodal neural network or MMN), we can call the hook for the CNN and merge it via simple concatenation into the final MMN.
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.cnn = CNN()
self.cnn.model.layer4[1].conv2.register_forward_hook(get_activation('layer4'))
self.mlp = Net()
self.mlp_ft = Net_Ft()
self.mmn = MMN()
def forward(self, image, landmarks, features):
outputs_im = self.cnn(image)
FM = activation['layer4']
FM.to(device)
outputs_lm = self.mlp(landmarks) # torch.Size(batch, 84, 7, 7])
outputs_ft = self.mlp_ft(features) # torch.Size([batch, 4, 7, 7])
# concat features from all modalities
z = (torch.cat((FM, outputs_lm, outputs_ft), 1)) # torch.Size([batch, 600, 7, 7])
# takes the concatenated features through the MMN
x = self.mmn(z) # torch.Size([128, 3])
return xThe reason why representations are important and why I went through all this trouble is that for this approach (aggregated fusion), I needed to project each multimodal feature of the different modalities into the same latent space. A little messiness is encountered in trying to ensure the tensor sizes coming out of each modality are the same so that the concat works.
Conclusion
Well, I hope that offered some idea of how MMAI is built. In summary, here are a few highlights:
- Multimodal refers to multiple data types, fancily called "heterogeneous". This can mean a motif like image, text, and audio, or, within-the-modality like visible and thermal imagery.
- MMAI (Catherine's definition) is when you train an AI algorithm or a system or algorithms on these modalities together. At test time, you might only pass one modality through (e.g. an image) with the expectation that the model has learned sufficiently discriminative features to map the image, let's say with text, so that the desired output is a caption. In other words, at test time, you give the AI one, some or all of the modalities.
- MMAI is not a new idea. MMML was shared in 2017 and even before that, it's well known in emotion/affective computing, that joining signals like sentiment and text, improve algorithm accuracy. But, the method to fuse joint representations and when during training (early, late) is an active area of research.
- Each AI task - whether it's text-to-video or multispectral image classification - is unique and different. As a result, there is no single "universal" multimodal fusion method that can be applied across the board.
- A simple and very effective method, is to use an "aggregate-based fusion" strategy. Simply put, several neural networks are used as feature extractors to learn each modality's latent representation. We then join them together through something as easy as concatenation during the training of the entire AI system.
If you liked this and found it useful - let me know! Till next time...