Taking a look at "How do Deepfakes Move?"

I read an excellent paper this morning by Demir from Intel and Ciftci from Binghamtom University entitled How do Deepfakes Move? Motion Magnification for Deepfake Source Detection, published at CVPR. They also published FakeCatcher: Detection of Synthetic Portrait Videos using Biological Signals.
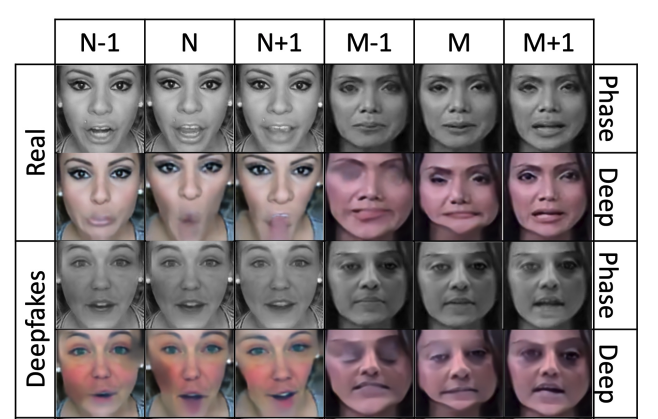
The paper posits that by analyzing features of deepfake motion magnification, it will not only detect with high accuracy if the video is real or fake - but also reveal the generative model, itself. This is possible because generative models essentially eliminate motion magnification due to the amplification of synthetic noise. In simpler terms, real videos (pristine) will follow human facial muscular patterns classified in the affective computing literature as Facial Action Units (AU)s below. These movements from frame-to-frame are motion magnification vectors which are stable for pristine videos but fragile for deepfakes. Generative models like GANs will overpower this subtle information of how the muscles move because too much noise is used to generate the fake image. As a result, the generated noise is amplified and not the muscular motion.

Another novel contribution of this paper is that unlike many deep learning deepfake detection algorithms which are essentially binary classifiers (real or fake?), their approach detects the actual source generator. This means formulating the problem as a multiclass classification issue and detecting if the video was made by FSGAN, W2L, Deepfakes, Face2Face, FaceShifter, FaceSwap, or NeuralTex.
Motion Magnification
The paper's focus on motion was inspired by physiological inputs such as heart beat and blood flow (see their FakeCatcher paper), that use human movement as a watermark. In their approach, the key element is inputting a combination vector made of shape and texture representations from deep motion magnification and phase motion magnification vectors.
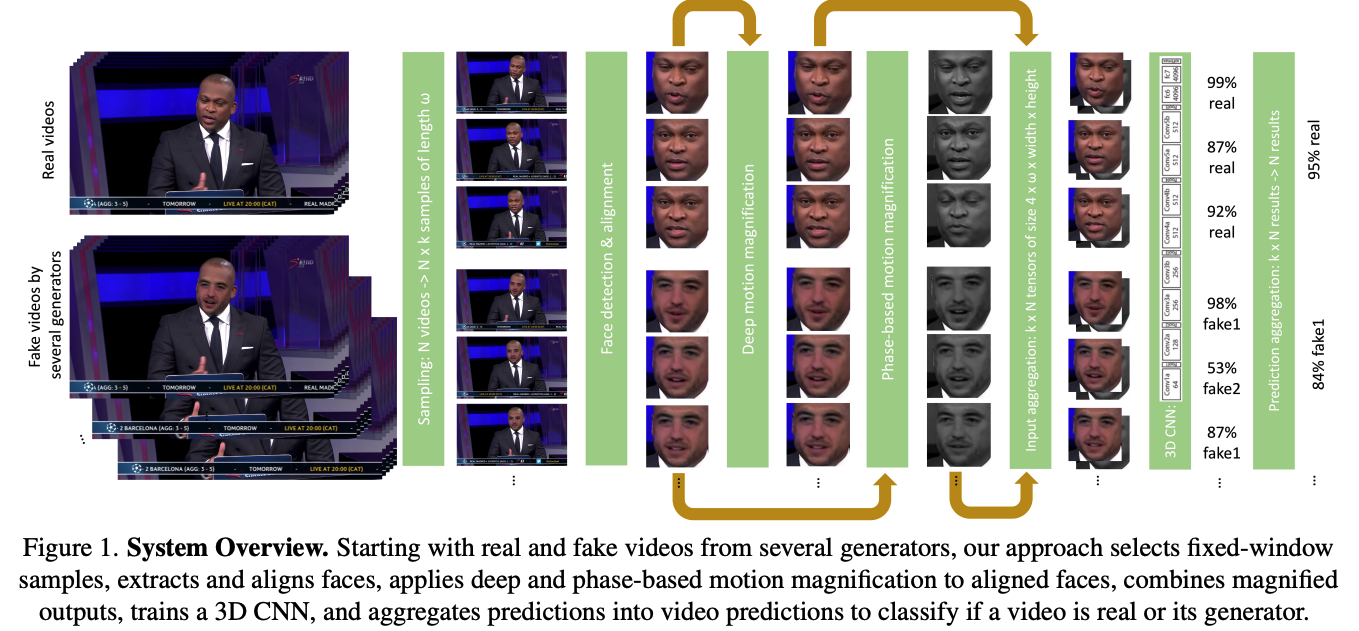
They use deep learning motion magnification and phase-based magnification. Deep learning using a CNN captures the overall shape representation of motion from frame-to-frame and a textural vector. But because it doesn't capture more subtle movement, they also pair it with a Eulerian phase-based magnification model per Wadha et al below.


Phase-based magnification is good for detecting imperceptible changes by evaluating local motions in spatial subbands of an image. This seems to make sense since phase is about the position of the waveform at any point in time, and characterizes its relationship with other waves forms (e.g. in-phase or out of phase). Personally, this reminded me a lot of what I learned in my dissertation when I integrated a Fourier Transform Loss that included both the amplitude and the phase of the image signal into the Visible Thermal Facial GAN. Now, it is the combination of both the deep learning vector and the phase vector that is passed to the simple multi-class 3D CNN that performs the deep fake detection.
Parameters
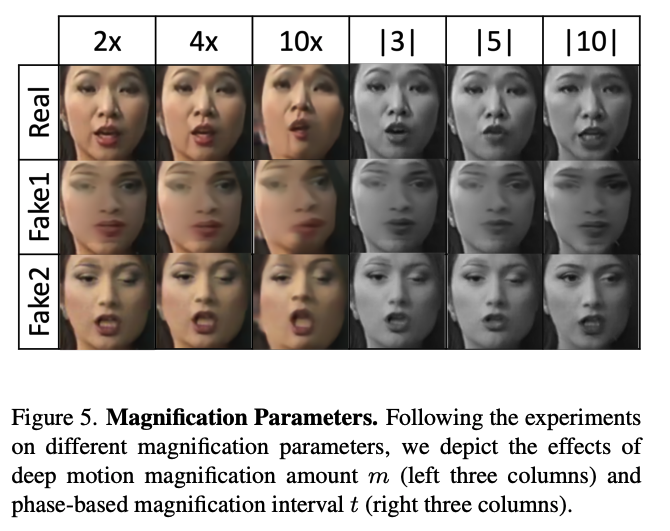
Ablation studies demonstrate that both motion vectors are necessary to achieve the 97.77% video source detection accuracy. In the paper, multiple parameters are listed to include number of frames, sample interval, window size, width and height. But, the amount of magnification is also a very significant parameter when it comes to motion magnification. Over-magnification by setting m=10x can lose the generative signal. By keeping m=2x (small), and using a 5-frame window for the phase model, the best detection occurs.
Conclusion
The biggest question I have about this paper is exactly what information the deep motion vector offers the approach, as opposed to the phase vector? For example, a phase vector with window size t=5 (85.61%) outperforms a deep vector of m=4 (83.16%). Are there certain frame samples that work better than others - such as large movements like head turns or up and down head bobs - that are less successful? It would be helpful to see samples of videos. Of note, they mention that a larger sample interval (more than 16 frames at a time), doesn't seem to work and that by averaging many samples of k=16 across a video would give you the overall video detection result. So, perhaps this is the case. That there are certain movements that are "too small" or "too big" to catch with their approach.