Detecting Deep Fakes

I don't have to tell you that everything we see online nowadays is increasingly suspicious. In our age of Generative AI and jaw dropping Tik Tok filters, it's hard to know what's real or what's fake. Since my dissertation was focused on generative imagery, I grew a robust side interest in deep fake detection. Here's a very easy primer on what deep fakes are, various methods, and an overview of datasets. For me, I'm profoundly fascinated in the ability to distinguish what Ilke Demir of Intel Labs calls "watermarks of humans" - the physiological signals such as heartbeat (ballistocardiogram), blood flow (photoplethysmography), vesemes (mouth shapes), blinking, and corneal speculation - as a means to distinguish real videos from generative residue. In my dissertation, I studied thermal physiology and analyzed vessels extracted from thermal facial images to propose a non-visible biometric. As a result, I have some vested interest in the marriage between physiology and generative AI.
What is a Deep Fake?
Deep Fake (a combo of terms from "deep learning" and "fakes") emerged in 2017 and is typically created from a generative deep learning algorithm that creates or modifies facial features in a super-realistic form making it difficult to distinguish between real and fake features. But, there's a simpler definition by Mirsky and Lee from 2020:
"Believable media generated by a deep neural network."
Zhu et al provide a nice overview of the basics of deep fake lgorithm like the infamous FaceSwap.
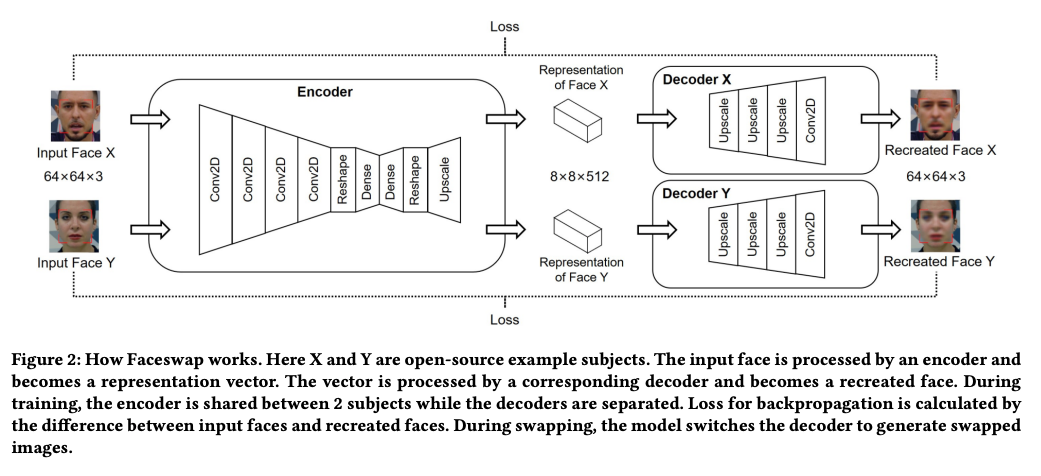
Two autoencoders with a shared encoder are trained to reconstruct training images of the source (X) and the target (Y) faces, respectively. A face detector like OpenFace is used to crop and align the images. To create a fake image, the trained encoder and decoder of the source face is applied to the target face. The autoencoder output is then blended with the rest of the image using Poisson image editing. FaceSwap uses a combination of generative algorithms such as an autoencoder (used in tasks like reconstruction) and traditional image blending (Poisson blending for image composition). A recent paper on "Deep Image Blending" offers a nice explanation for those of you who want to learn about deep learning-based advances in image blending.
"The current most popular method for image blending is Poisson image editing. The idea is to reconstruct pixels in the blending region such that the blending boundary has smooth pixel transition or small gradients with respect to the boundary pixels in the target image."

It's remarkable that one of the key methods in deep fake generation, Poisson blending, was developed back in 2003 by Microsoft. Take a look at the original paper I linked and you'll notice several figures of examples comparing Poisson image editing under different cloning configurations.
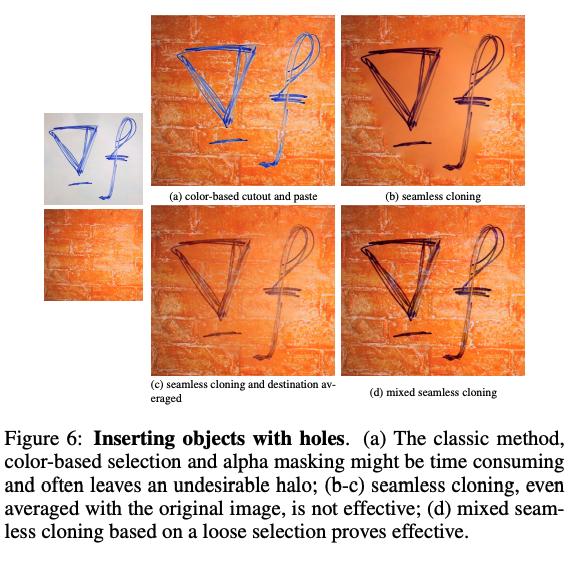
The intuition for how Poisson blending works mathematically (and psycho-perceptually) is also fascinating. Perez et al remark that:
First, it is well known to psychologists [Land and McCann 1971] that slow gradients of intensity, which are suppressed by the Laplacian operator, can be superimposed on an image with barely noticeable effect. Conversely, the second-order variations extracted by the Laplacian operator are the most significant perceptually.
Secondly, a scalar function on a bounded domain is uniquely defined by its values on the boundary and its Laplacian in the interior. The Poisson equation therefore has a unique solution and this leads to a sound algorithm. So, given methods for crafting the Laplacian of an unknown function over some domain, and its boundary conditions, the Poisson equation can be solved numerically to achieve seamless filling of that domain.
Types of Deep Fakes
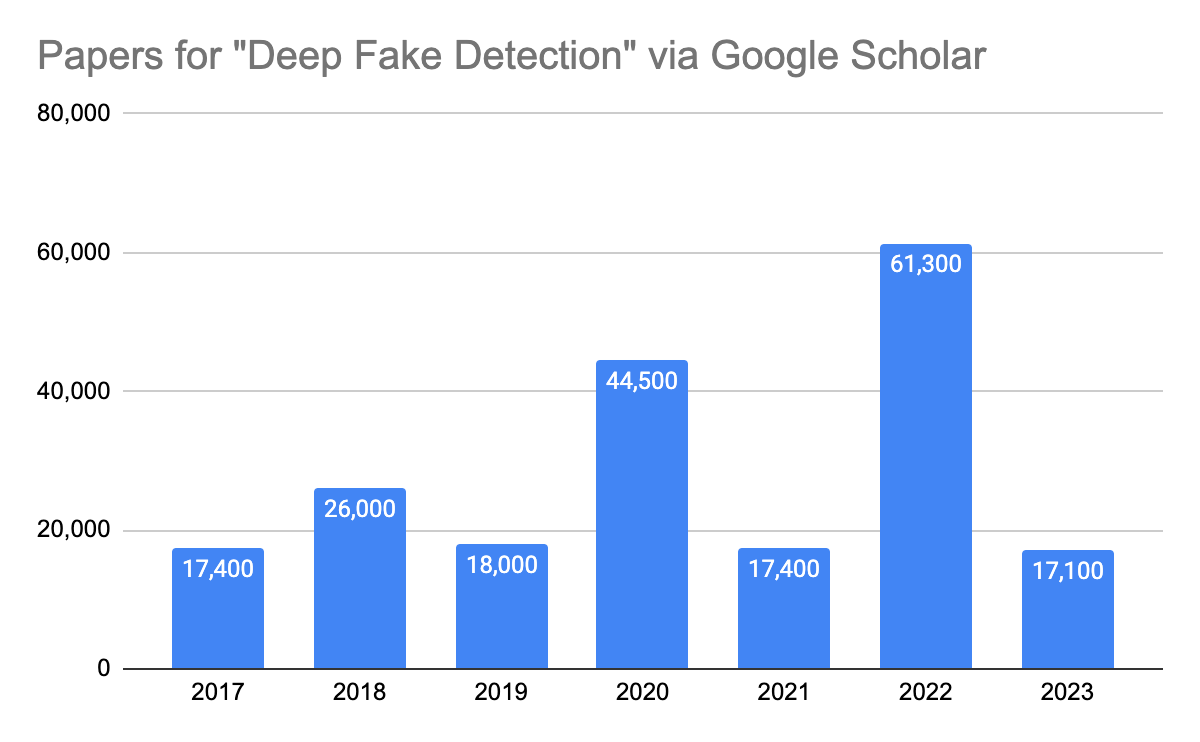
Dozens of thousands of papers are fighting the battle against deep fakes. Today there are numerous works beyond the realm of autoencoders and Generative Adversarial Networks (GANs), taking researchers in Denoising Diffusion Probabilistic Models (DDPMs), or, diffusion models. I ginned up the chart below to show how research is definitely on an upward trajectory with a dip last year (probably because LLMs have been all the rage, lately). Still, despite the advances in deep fake detection, the onslaught of face manipulation software is a plenty!
You can generate fake visual content through multiple methods that don't even rely on AI. These include 3D face modeling, computer graphics rendering, and manual image warping through a tool as easy as Photoshop. You can swap faces while keeping expressions intact (e.g., DeepFakes, FaceSwap) or by facial expression transfer called reenactment (Face2Face). Most recently, I tried a new Midjourney / Discord plugin called Insight Face and it works pretty well, too.
Here are different forms of face manipulation that can be achieved with AI generation. Some of these generate complete or only partial features, which makes it even more challenging to detect.
- Completely new face generation using GAN or Diffusion Models (e.g. StyleGAN2, Midjourney, thispersondoesnotexist)
- Identity Swap – What we typically think of when we hear “DeepFake”. It replaces the face of one person with another on image or video (e.g. FaceSwap).
- Attribute Manipulation – Modifying some facial features such as hair, eye color, facial hair, hats, glasses. (e.g. StarGAN)
- Expression Swap – Change the facial expression such as happy to sad (e.g. Face2Face)
- Face Morphing - Combines two or more subjects so that the resulting face resembles both.
- Face Deidentification – Remove biometrics from facial images through blurring or pixilation.
- Audio2Video & Text2Video – Learning lip-sync from audio (“Synthesizing Obama”, 2017)

Face2Face
Face2Face was published by the Technical University of Munich at CVPR in 2016 as "Real-time Face Capture and Reenactment of RGB Videos". It implements real-time facial reenactment based on markerless facial performance capture akin to the animation of virtual CG avatars in video games and movies. The incredible aspect of Face2Face was its ability to execute online transfer of facial expressions, meaning directly transfer a source actor's facial expressions captured by something like a webcam directly onto the target actor without waiting.
A synthesized image is generated through rasterization of the model under a rigid model transformation. The structure depends on a face model, illumination, rigid transforms, and camera parameters. During training, the model learns a loss to minimize the error between what's synthesized and the input data to encourage photorealism and facial alignment. The model relies on facial landmark tracking to map each facial feature point and score confidence along features and 3D vertices. As such, the expression transfer is accomplished by calculating deformation gradients of the mesh based on the matrix that contains edge information about the facial template. What's most interesting is how the mouth is used as a critical shape matching feature. Mouth image are retrieved to find the best matching mouth from the target actor sequence using a similarity metrics by selecting mouths from an appearance graph learned over frames of video.
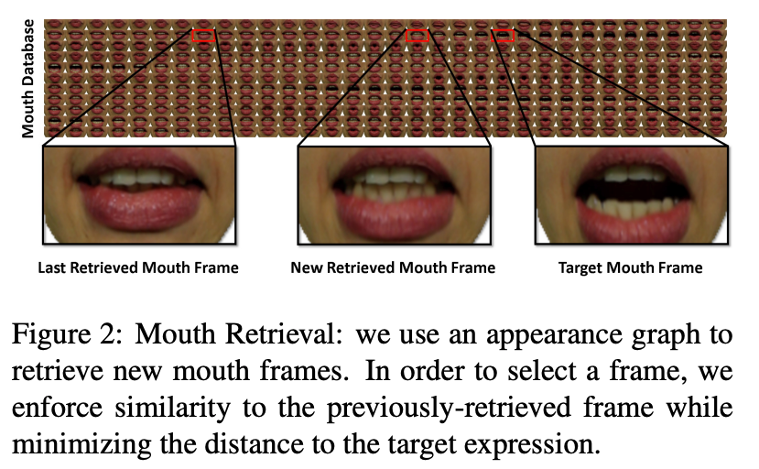
Face Morphing
With face morphing, two or more subjects are combined in a way where all contributing subjects are verified successfully against the morphed image. This is to say, two people can live under the same identity via a government document like a passport. This is exactly what happened in 2018 when a German art activist used face morphing software to obtain an official German passport using a digitally morphed photo. The photo is morphed with her own facial features and that of Federica Mogherini, an Italian politician who is the High Representative of the European Union for Foreign Affairs and Security Policy.

Face morphing poses a severe threat to systems where face recognition it used to establish the identity of subjects. A criminal can exploit the passport of an accomplice with no criminal records to overcome the security controls. The accomplice could apply for an electronic passport by presenting the morphed face photo. And if the image is not noticeably different from the applicant face, the police officer could accept the photo and release the document.
The idea of combining faces together into a new one isn't new. It was introduced in a famous paper published almost a decade ago called The Magic Passport. Here, the authors list the manual steps required to create a single good morph. For example, first find two faces and make them into separate layer and superimpose the eyes. Then, manually mark up facial features (i.e. eye corners, nose tip, chin, etc.) using a software tool which will create a sequence of transitioning facial frames. The tool will then output a score for matching the most similar or desired facial image. Lastly, manually retouch the image to make it more realistic by eliminating shadows and other artifacts.

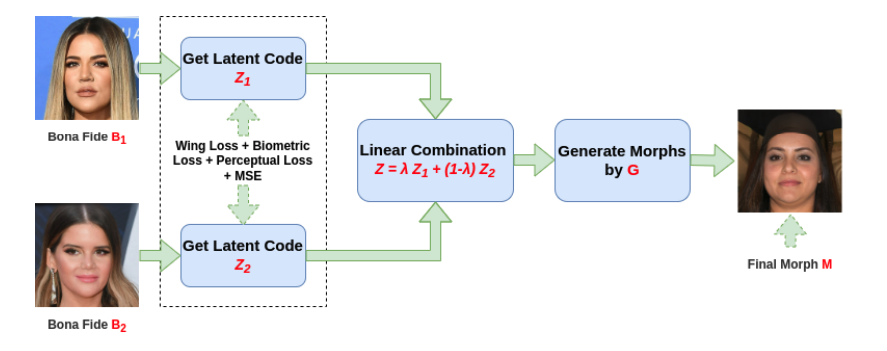
But as we now know, all of this can be done automatically like MorphGANFormer. The idea is to generate a very photorealistic (and criminally passable) face by training the model to score high (or low error) between the morph, M, and its templates A and B - or in the figure below both of the bona fides.

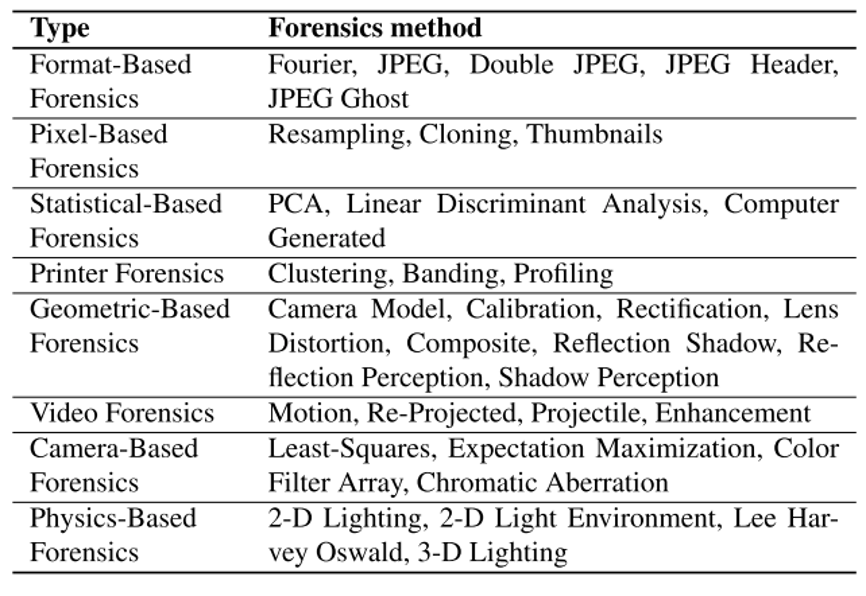
Deep Fake Detection using Traditional Forensics
There are "active" and "passive" forensics for deep fake detection. Active forensics requires prior knowledge of multimedia such as a watermark that has been tampered with or using facial recognition to assess authentic expressions (e.g. image classification technique). This might include extracting a watermark that has been tampered with. Whereas, passive forensics needs no prior information. It relies on statistical information about the image or video using pixel- statistical- geometric- video-, camera-, and physics-based forensics. These include Fourier Transforms, PCA, Least Squares, Motion Magnification, and others that fall under pixel, video, camera, and physics-based forensics.
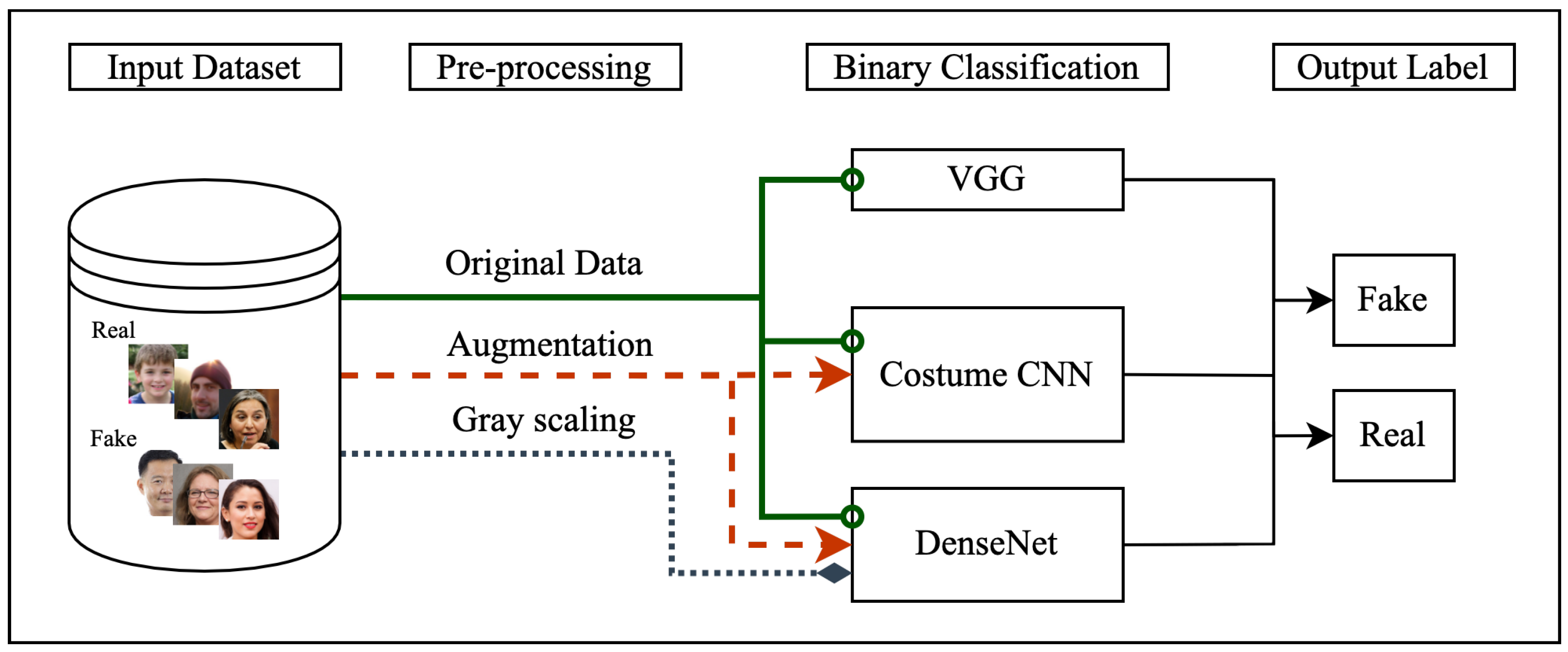
Deep Fake Detection using Deep Learning
The overall goal of deepfake detection is to classify the input media as either real or fake, and as a result most methods are formulated as a binary classification problem.
All published works in deep fake detection attempt to benchmark their algorithms against existing deep fake datasets. See below for a chart on three different types of deep fake datasets.

Since many of the detection methods are binary classification tasks, they can fail on unseen data (like the "unknown source" types). Other methods try to increase generalization of deepfake detection models but assume that the fake images share similar properties introduced during generation such as blending boundaries, geometric features, frequency features. These assumptions are only a human’s perception of the artifacts and may not be true in real-life deepfake scenarios (Dong, et al). Further, since many of the existing methods are detecting if it was fake or not, the problem may be framed too simplistically. This is especially the case if the detection algorithm can only detect artifacts from a handful of GANs like CycleGAN, StarGAN, or StyleGAN, despite the hundreds of methods that are GAN or transformers-based that now exist. Further, as we just learned, the entire facial image is often times not altered. Many times, it is only a small part (like the mouth), and some methods classify the entire image as opposed to a fraction of it.

Artifact Analysis and Biological Signals
I think the most promising direction for deep fake detection - be it on static images, video, or now, multimodal deepfakes with audio - is detecting what makes it human (or not). To this extent, algorithms in on temporal or physiological signals. There are fluctuations in a person's behavior from frame to frame, coherence, and video frame synchronization that can tip off a viewer on whether the video has been generated. Noise analysis on static images is a standard way of inspecting synthesized content.

Some methods have ensembled individual backbones (i.e. ResNet-18, Xception, Mesoinception4) to learn individual facial features - as opposed to the entire, global image.
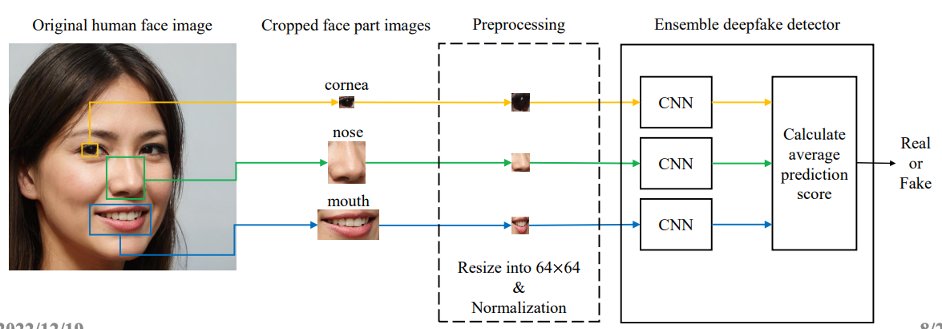
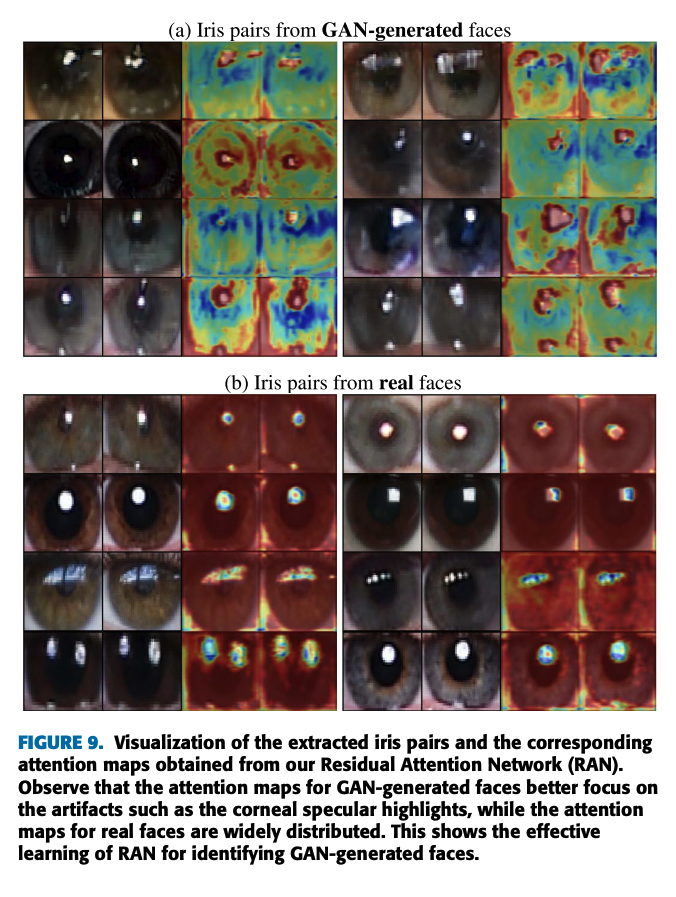
The lack of eye blinking, changes between 3D head pose movement such as orientation and position, eyes, teeth, and facial features are all types of detecting visual inconsistency of biological signs. These also include finding incident illumination or inaccurate geometry from reflections and texture, gaze. Some like Guo et al have investigated the correspondence of how light bounces off the cornea via corneal specular highlights and iris matching.
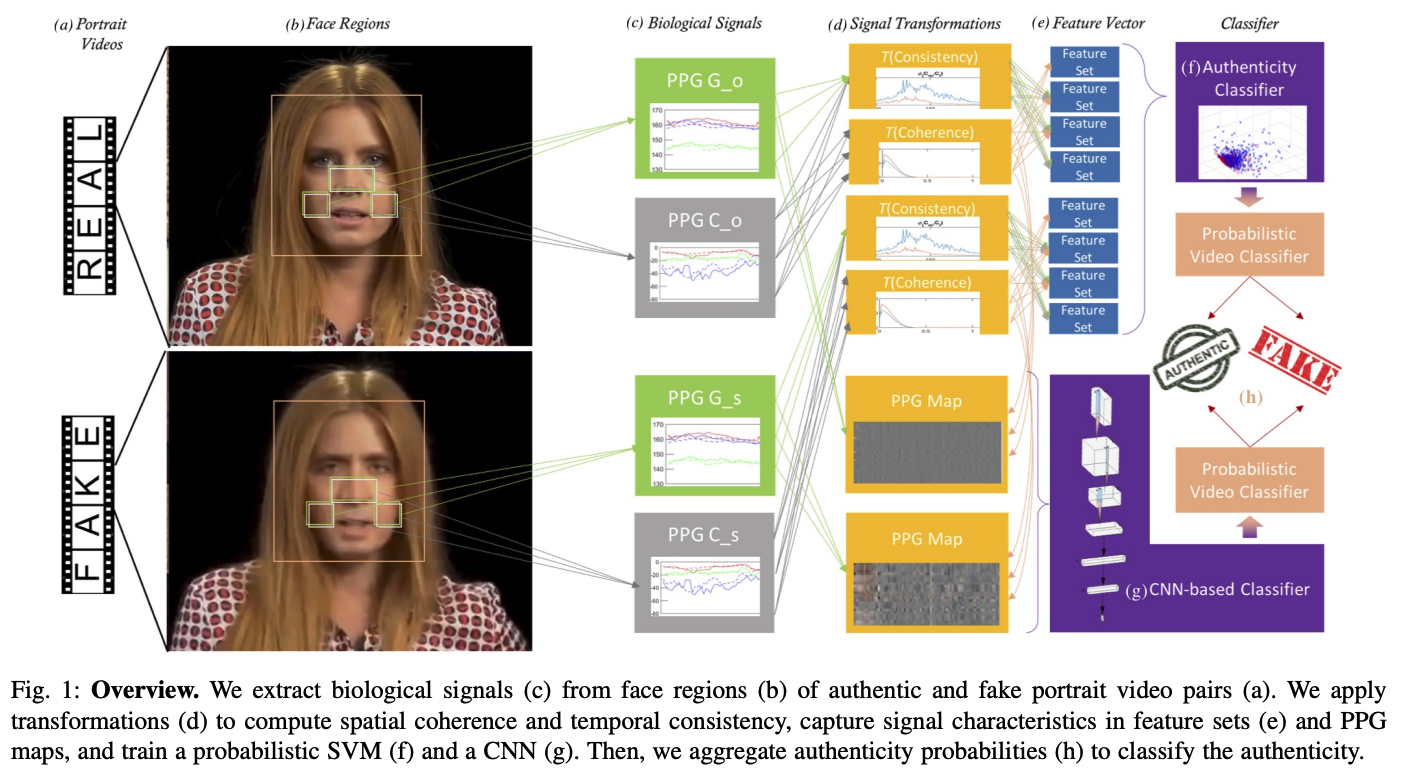
Changes in subtle color changes in the face is used to infer blood flow, a process called photoplethysmography (PPG).
Researchers like Demir et al, prove that video generators will actually eliminate the PPG signals since generative spatial, spectral, and temporal noise interferes with the color information - that would otherwise say the subject is human.
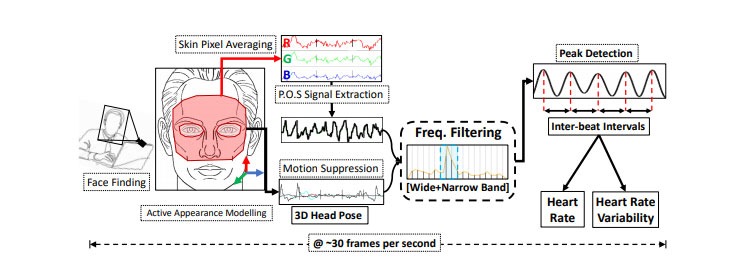
Whereas, in the Deep-Rhythm paper Predicting Heart Rate Variations of Deepfake Videos using Neural ODE, the authors analyze ballistocardiogram (BCG) techniques for heart rate detection from facial videos. Heart rates were extracted from deep fake videos using three standard approaches: facial skin color variation, average optical intensity in the forehead, and Eulerian video magnification by MIT (gif below).

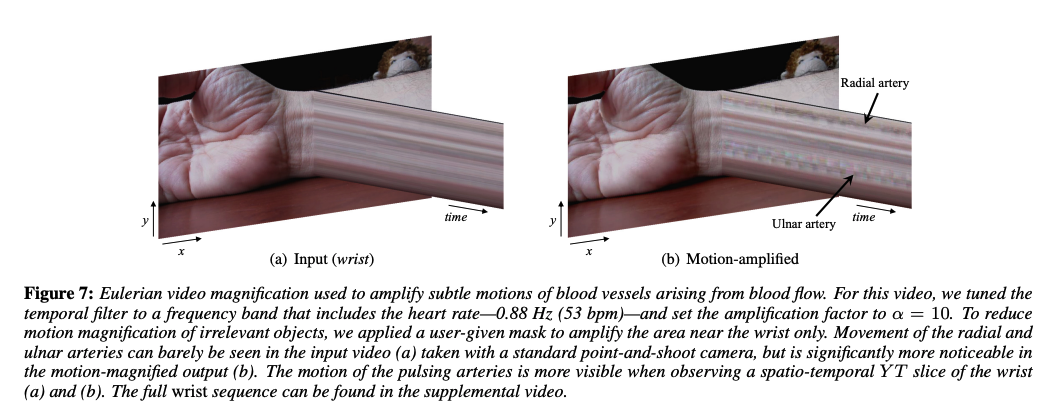
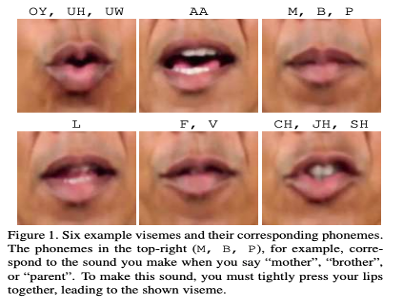
Others study visual-audio irregularity. In Emotions Don’t Lie, the authors train a Siamese network on a multimodal audio-visual "perceived emotion" embedding. It contains facial feature information as well as Mel Spectrogram coefficients extracted from the audio of real and fake videos. In Detecting Deep-Fake Videos from Phoneme-Viseme Mismatches, the algorithm learns mouth shape dynamics (vesemes) and the pronounced phoneme. I found this really interesting since there is a temporal pattern with sounds like “mama”, “baba”, and “papa” phonemes that require lips to be totally closed. The network is trained using videos of Barack Obama for whom the lip-sync deep fakes were created in the A2V dataset. In total, the authors manually labeled 15, 600 video frames where the mouth is open (8258 instances) or closed (7342 instances).
Conclusion
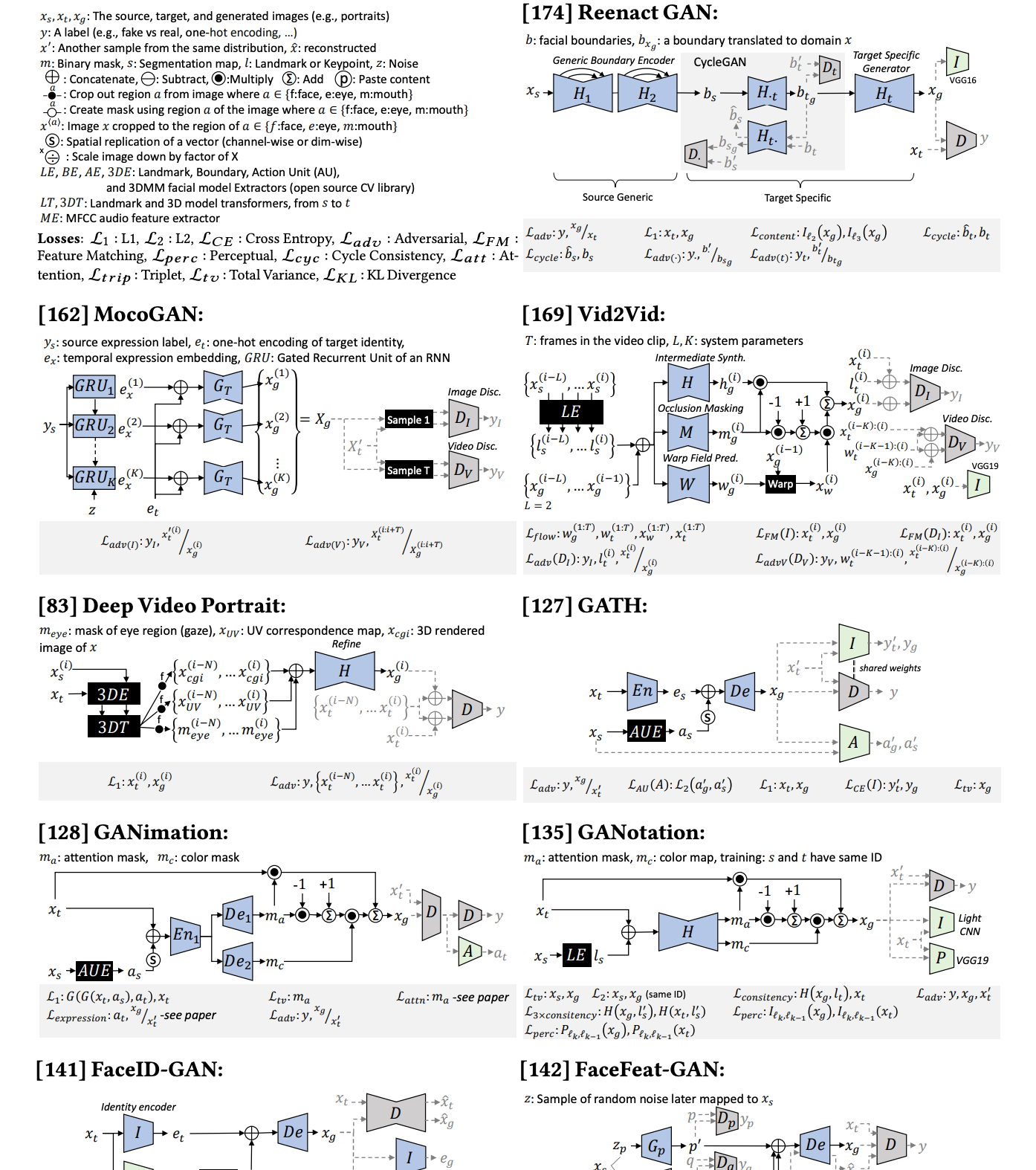
As you'll easily appreciate once you read any of the survey articles I linked below (the first by Mirksy and Lee, I'd recommend), is that there is an almost never-ending, infinite configuration of generative architectures that can synthesize deep fakes. You can tell with the below diagram that it was written pre-transformers when GAN was the only show in town. Now, there are more ways to generate deep fakes than ever before as the technology advances and compute frees up.
As a result, like any security system, the onus will be on industry and researchers to keep up. But, the challenges, in my personal opinion are hard to defeat with any single, universal algorithm alone. As you read in this post, it seems (and this should be no surprise), that a multimodal approach is absolutely necessary when it comes to the latest deep fake videos. Voice clones are incredibly good and becoming commodity at this point. Video imagery is also indistinguishable from reality. And with the torrent of content that we're barraged with every second and minute, the ability to quickly detect truth from lie is impossible. Not only is a multimodal approach necessary but one that relies on human-only watermarks - things that an algorithm would naturally disregard in the learning process in favor of noise. I suppose, that is, until deep fakes attempt to learn some objective that would optimize human blood flow or heartbeat patterns. Philosophically, it's somewhat of an existential matter - to train an AI as a human detector in order to thwart an AI that was a poor human generator.
Anyway, before I delve into scifi - cause this is where it's heading now!... let me leave you with a few papers to sink your teeth into.
- The Creation and Detection of Deepfakes: A Survey
- DeepFakes and Beyond: A Survey of Face Manipulation and Fake Detection
- Deep Fake Detection: A Systematic Literature Review
- A Survey on Deepfake Video Detection
- A Review of Modern Audio Deepfake Detection Methods: Challenges and Future Directions
- Media Forensics and DeepFakes: an overview
- Countering Malicious DeepFakes: Survey, Battleground, and Horizon
- A Comprehensive Review of Deep-Learning-Based Methods for Image Forensics