Can Language Agents Play RPGs?

I'm getting back into it after a holiday break and one of the most fascinating areas of AI research is Language Agents. I'm more of a computer vision person, so LLMs are not my bread and butter. But, I've grown increasingly interested in the various metaphors and constructs used to technically philosophize LLMs. I read a paper today, and yes - to answer my question - yes, they evidently can. Here's a review of a cool paper that was mentioned in this week's Turing Post - LARP: Language-Agent Role Play for Open-World Games.
The paper discusses a “cognitive architecture” for how to integrate memory processing and decision-making so that a Language Agent could ostensibly play an open world game. Specifically, the goal is to have the system output tasks or dialogue for a Non-Player Character (NPC).
Like, in a game such as Dungeons & Dragons, NPCs are controlled by the Dungeon Master. They can take on roles such as quest givers (i.e. provide objectives to players and send them on quests), act as an ally or adversary, be a service provider like an innkeeper or blacksmith, offer information like clues such as a sage, and overall comprise the world by embodying cultures and history.

Again, the overall goal of the LARP system is to equip the NPC with diversified behaviors. But doing this is challenging because it requires a variety of challenges that are not yet solved by Language Agents. The authors list interpreting complex environments, memorizing long-term events, generating expressions consistent with character and environmental settings, and continuously learning from the environment. One they mention later that deserves mention earlier in this list, is the diversity of personality and quality of data that comes in pre-training a LLM to act as such.
First, it’s modular, meaning that there’s (what I assume), code/functions, that implements memory processing, decision-making, and continuous learning from interactions. This is synonymous with the typical agent system that consists of i) memory, ii) planning, and iii) tool use.
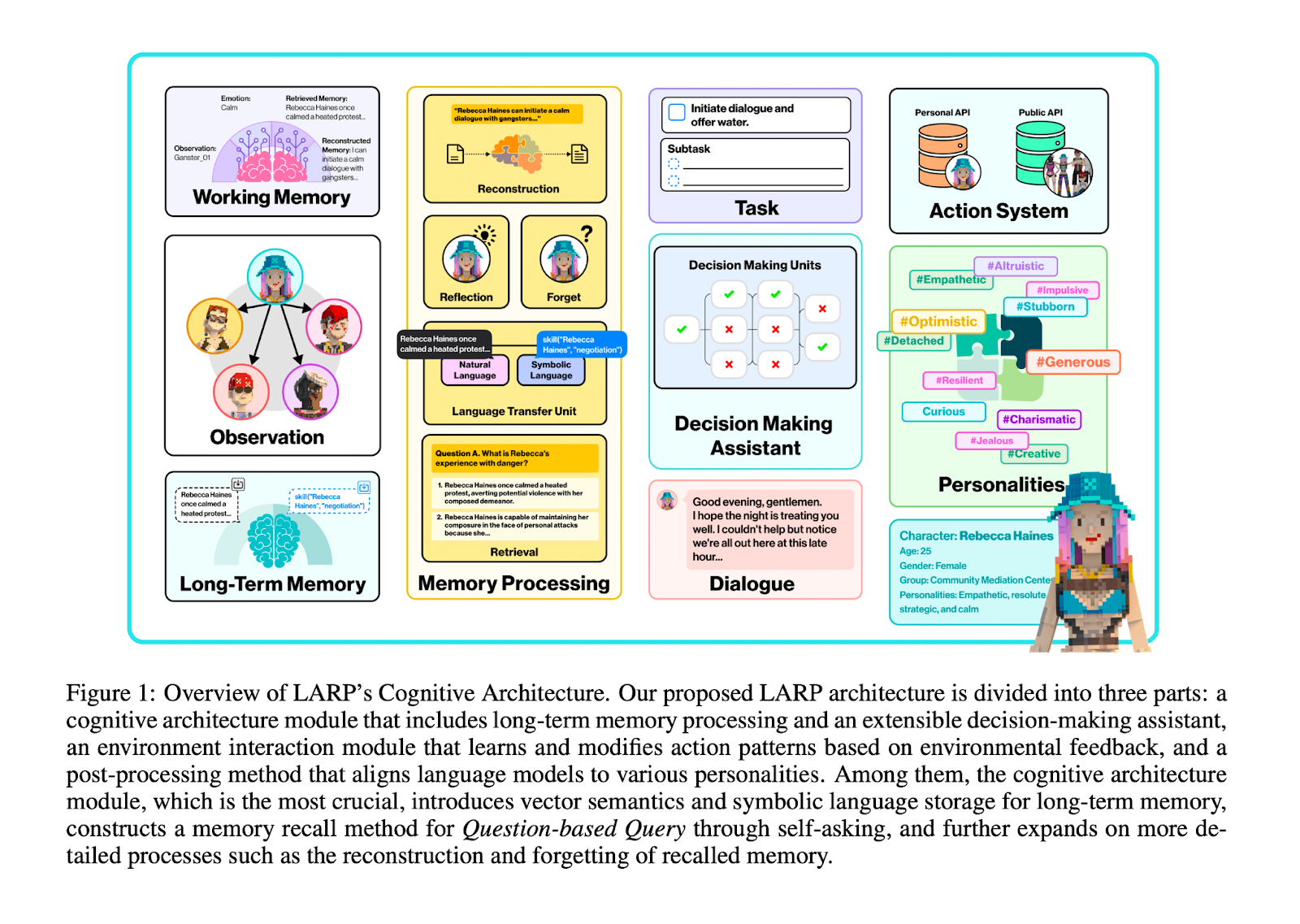
The LARP Cognitive Architecture has 4 Modules
Like the paper's figure above: i) long term memory, ii) working memory, iii) memory processing, and iv) decision-making. Their long term memory module is inspired by human declarative memory and is divided into a) semantic and b) episodic.
"Declarative or explicit memory is devoted to processing of names, dates, places, facts, events, and so forth. These are entities that are thought of as being encoded symbolically and that thus can be described with language. In terms of function, declarative memory is specialized for fast processing and learning. New information can be entered into the declarative memory system on the basis of a single trial or experience."
Semantic refers to facts like rules of the game and episodic are experiences such as information about other players or Agents. They mention that some kind of external database is used for storing game rules and that vector databases are used to store and retrieve the episodic memory. The most interesting memory they mention under long-term is “procedural memory” which is a set of actions or skills that can be performed without conscious thought. We’ll see later that this is essentially a database of APIs. Working memory, on the other hand, is like a cache where everything processed from long-term memory is stored.
Memory Processing
This module takes information from the working memory module and passes them to “logic processing units” in the fourth module, the Decision Making module. The Decision Making module’s goal is to continuously update content in working memory. Reflection occurs once the working memory has reached a certain threshold. At this point, reflection is triggered meaning, memories are filtered out. This “filtering” is accomplished by a combination of vector similarity lookups and predicate logic (for me, I thought about logical programming languages such as old Prolog).
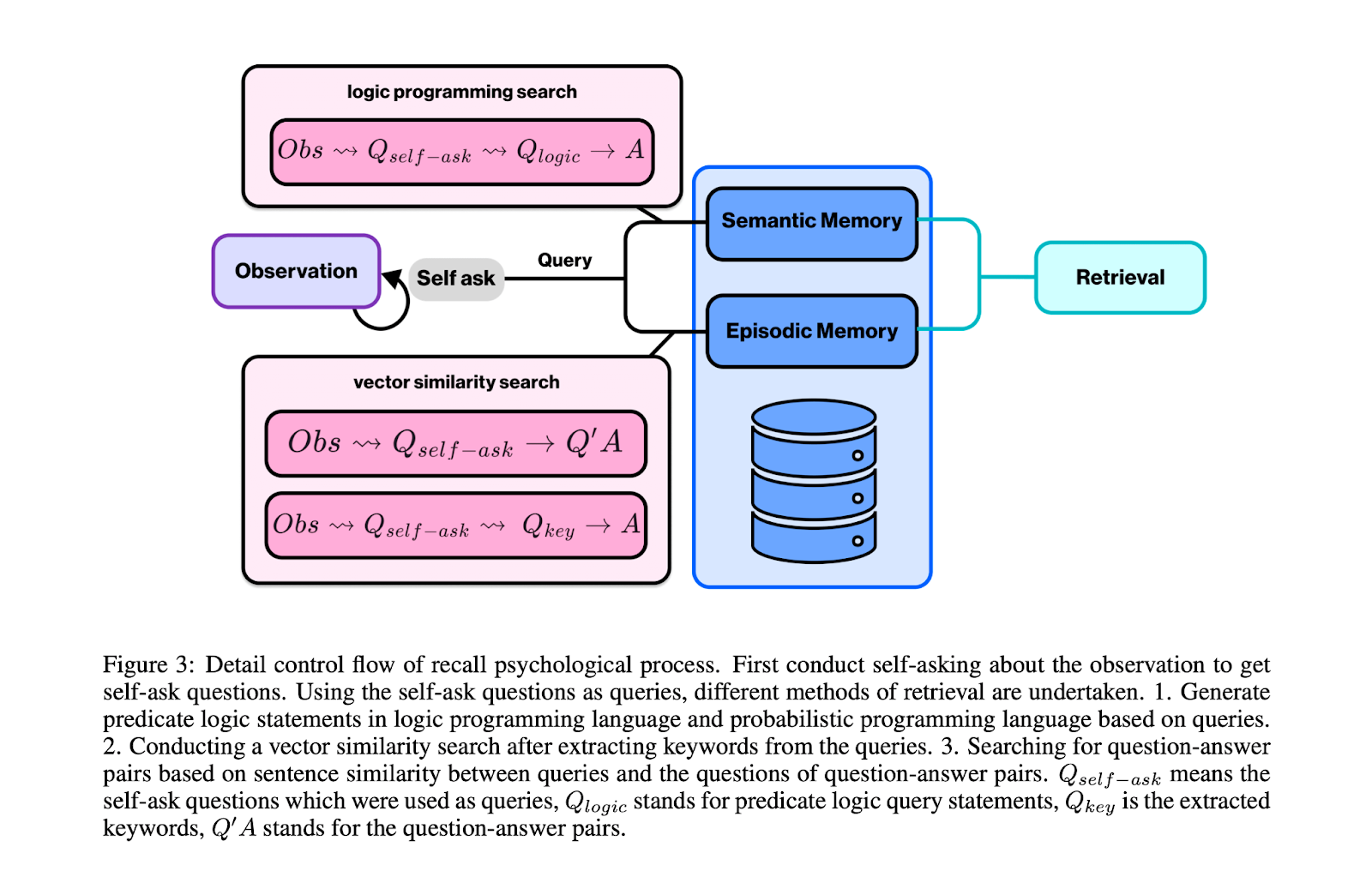
Forgetting
LARP uses Chain of Thought (CoT) (intermediate reasoning steps) to perform recall as many agents do. This is to enable the agent to reason about retrieved content that comes from long-term memory to be dumped into working memory. They enable “forgetting” by setting a decay parameter based on Wickelgren’s power law. I had to look this up because I had no idea what or who this was based on . Evidently, a classic law of cognition is that forgetting curves can be approximated by power functions with "remarkable generalizability and precision". Who knew!?
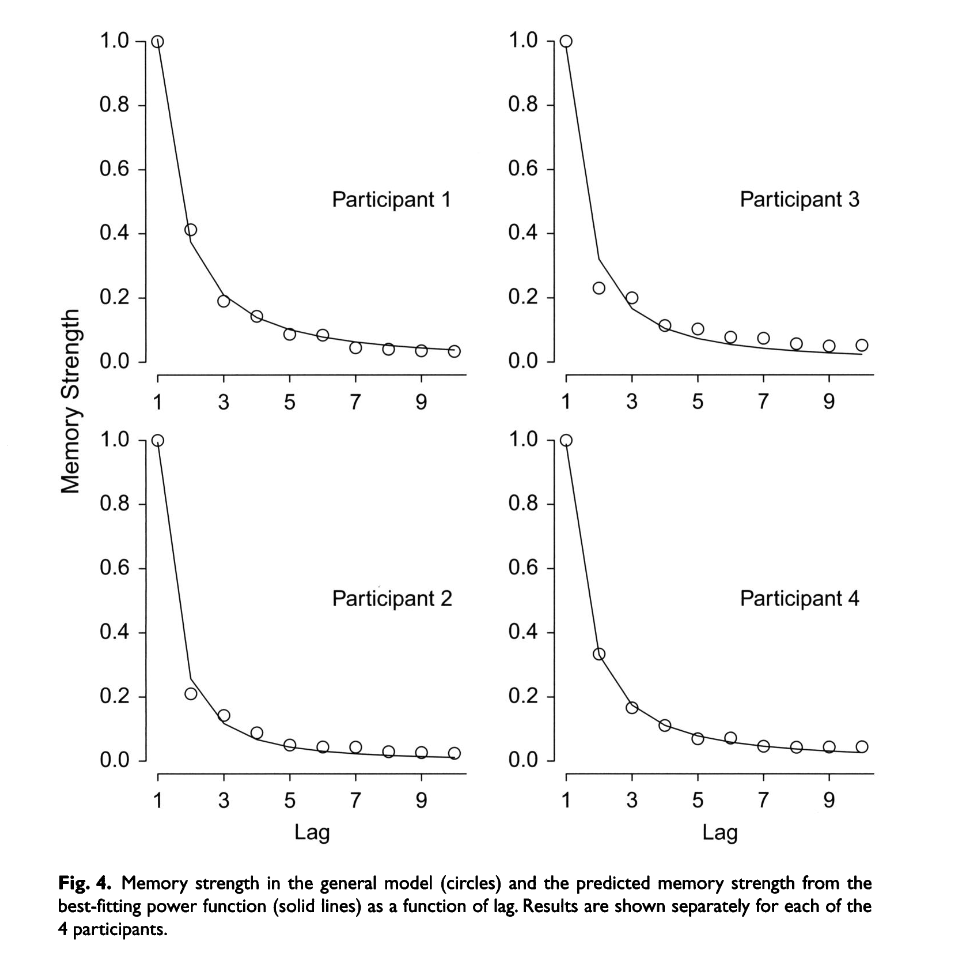
A lambda denotes an importance level of the memory/data. N is the number of retrievals of this specific memory, and t is the elapsed time after the last retrieval. Phi is the rate of forgetting for each NPC. Then, there are scaling parameters for each of these variables. The goal is to simulate instances of memory distortion. (It would be interesting to learn from the authors why memory distortion would be desired.)
Environment Interaction with API/Skills Libraries
I thought this was the most interesting design element. I imagine this is a standard method in Language Agents. But, it made sense for how they implement “procedural memory” as I mentioned earlier.
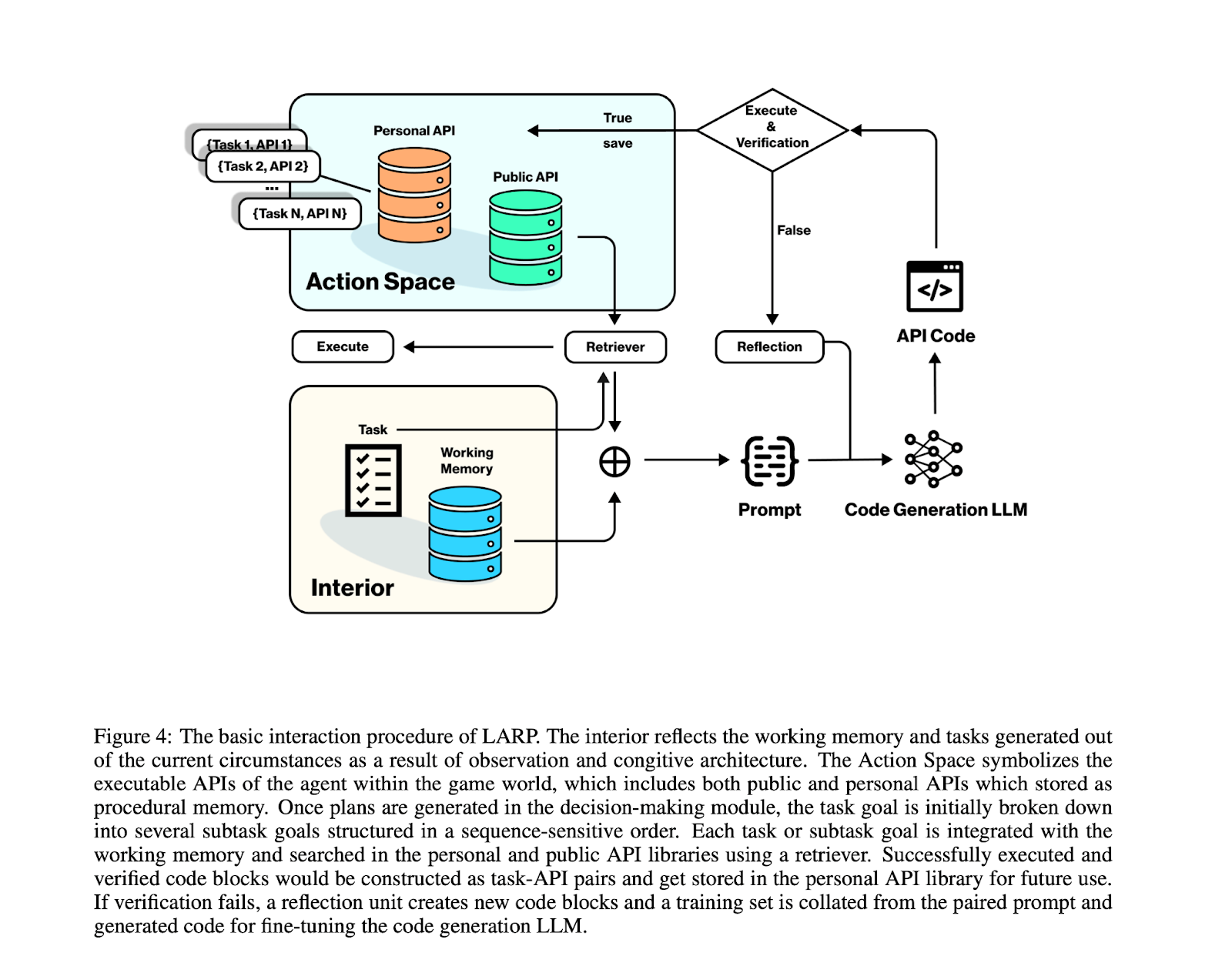
Essentially, systems like Voyager and Octopus, utilize “skill libraries” that achieve high extensibility to learn new skills mainly through the pairing of key-value prompts such as <prompt,code>. In LARP, the Action Space is all the executable APIs that the Agent can execute in its world. Some of these are personal to the NPC and some are public to the world. It’s pretty cool because it is essentially an API library that stores <task,API> pairs.
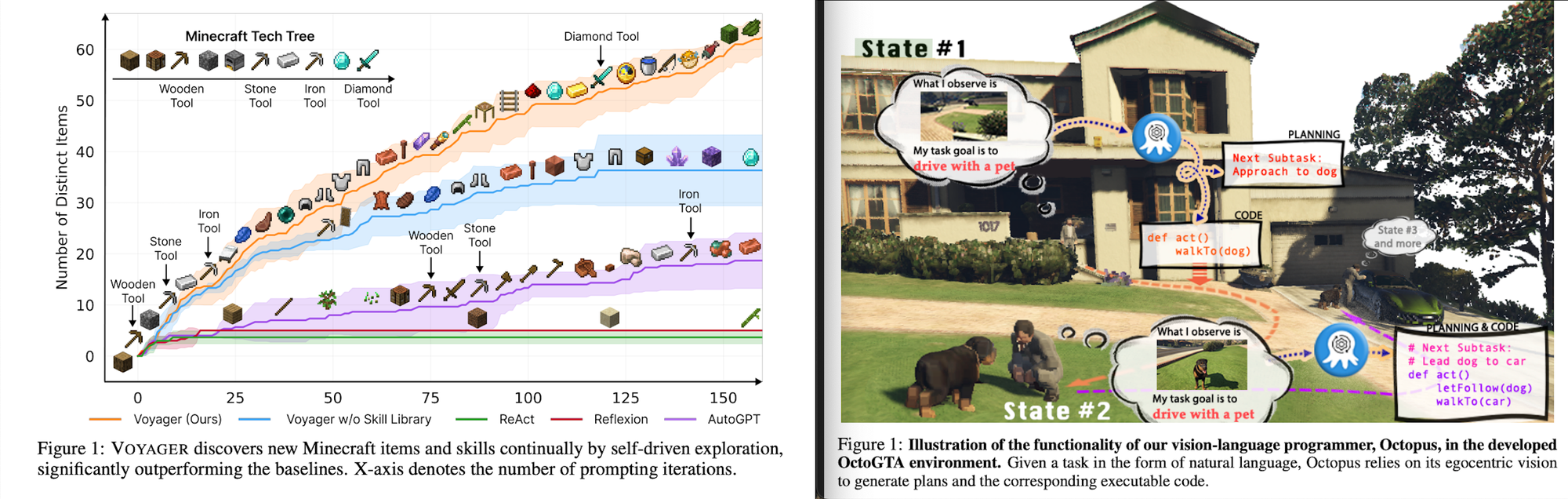
When a task for an NPC is generated, let’s say (and I’m making this one up) deceive an enemy, it will be broken down into sub-tasks: sing a magical song, make a wisecrack, etc. Each subtask’s goal is an ordered sequence-sensitive schedule. So then the retriever will search for such an existing pair in the Action Space. If it’s there, then that’s good, because it will reuse it, saving the cost of the Language Agent system. If not, then, the system will complete a corresponding prompt using a fine-tuned LLM. The prompt is a block of code to retrieve or build an API and goes through validation checks. If it fails, it goes back to “Reflection” (see previous). Then, the pair <prompt,code> is used as training data to fine-tune the LLM and fed back to RLHF (they didn’t mention how).
Acting out Different Personalities
Like I mentioned earlier, there could be a gruff sailor, an esoteric and wordy wizard, or a cheerful, bubbly innkeeper. The authors of LARP assert using a cluster of LLMs fine-tuned with datasets from “perspectives of different cultures and groups” via LoRAs. LoRA (Low Rank Adaption) introduced by Hu, et al from Microsoft is a parameter-efficient approach for fine-tuning. The idea with LoRA is that since we’re fine-tuning, you don’t need the entire full-rank weight matrix. Say you have a LLM with a weight matrix, W. When the model is updated, the weights will be updated by adding the changes of the gradients to W. This adds up after each optimization round. Instead, LoRA works by learning an approximation of the gradients matrix, or a “low rank” representation, say of two matrices A and B instead of the entire gradient. Then the update is W + AB, not W + Delta_W.
Returning to the paper, they assert that a bunch of LoRAs can be integrated together to capture different scales, creating a “model cluster” of diverse personalities. But the ability to find such data to fine-tune the LoRAs is another matter - literary creativity, scripts, character research, and more. One slight criticism I have of the paper is not disclosing the list of datasets? Or, moreover, offering verification how it works in practice.
Conclusion
Their Github repo is still under development, so I suppose we have to trust that the system works. Until then, I'll be reading about Voyager that learned how to play Minecraft and the Visual Language Model from Octopus. Automated learning through Language Agents is a fascinating and open-research field. One of the reasons I find it so interesting is how multidisciplinary the algorithms and methods are, pulling in from the reinforcement learning, computer vision, LLM, and logical AI domains.