PyTorch Pair-Wise Transforms and Data

Consider that you have a pair of images you want to train. In my case, it's a GAN, where I'm improving upon older work from 2020 in the facial-visible-to-thermal GAN. My paired image consists of a visible and thermal face, simultaneously captured from a single shot using a dual sensor. This example is from the Iris Dataset, an open source dataset captured using a bst ferroelectric thermal sensor from 2013. Here's an example below. I also provide a link on my UMBC Box account if you'd like it pre-paired on my Github repo provided above.

To perform any of the number of PyTorch transforms on paired images isn't that straight forward. After searching on the PyTorch forums, of course P.Black provided the answer here. There are a few data processing goals here:
- Create augmentations by applying the same transform on both images, in this case, the visible and the thermal.
- Add the augmented images to the set of regular, non-augmented images. Keep the "regular" images with the basic transforms like
resize,totensor,normalize. - When reading in mini-batches, ensure the indices are kept paired for both modalities, in this case the same index for the visible and thermal of both the "regular" and "augmented" datasets.
- Randomly sample from the augmented dataset so that a new batch of images is retrieved for augmentations.
- Randomize the indices so that the "regular" images are not always followed by the "augmented", but are rather shuffled randomly together.
Below is an example of how you could write a dataset class, dataloader, and a recommendation on pairing to ensure the correct indices are maintained as you read it in.
Dataset class
Let's call this datasets_augs.py. A key assumption here is that we're loading in the images as aligned pairs using this classic script from the pix2pix repo. As a result, we assume the image is a file loaded in as a pair, then cropped in half. The MainDataset() class is for loading our vanilla-plain old image pairs. When we get to the dataloader, we pass a very boring transforms_ for resizing, to-tensor, and normalizing. It's only going be passed to the MainDataset() class.
class MainDataset(Dataset):
def __init__(self,root, transforms_=None, mode="train"):
self.transform = transforms.Compose(transforms_)
self.files = sorted(glob.glob(os.path.join(root, mode) + "/*.*"))
def __getitem__(self, index):
img = Image.open(self.files[index % len(self.files)])
w, h = img.size
img_A = img.crop((0, 0, w / 2, h))
img_B = img.crop((w / 2, 0, w, h))
real_A = self.transform(img_A)
real_B = self.transform(img_B)
return {"A": real_A,
"B": real_B}
def __len__(self):
return len(self.files)The AugDataset() class is where the augmentations occur. You might ask, "Why not pass a transformation to this class, instead of doing it all inline?". The problem is, that since in our case we're working with an A and B image, cropped from the pair, PyTorch will treat this as two separate, unpaired, independent images. As a result, passing a transforms to this class will lead to independent transformations on A and B separately, not A and B jointly. As a result, we must use P.Black's recommendation to build the augmentations in the class per the def aug_transforms() function. Note, you can do a host of other transforms, but I'm just showing a few simple geometric transforms (flips) for illustration. The basic logic here is, whatever's done to A must also be done to B, and we return A and B together.
class AugDataset(Dataset):
def __init__(self,root, transforms_=None, mode="train"):
self.files = sorted(glob.glob(os.path.join(root, mode) + "/*.*"))
def aug_transform(self, A, B):
resize = transforms.Resize(size=(256, 256))
A = resize(A)
B = resize(B)
# Random horizontal flipping
if random.random() > 0.5:
A = TF.hflip(A)
B = TF.hflip(B)
# Random vertical flipping
if random.random() > 0.5:
A = TF.vflip(A)
B = TF.vflip(B)
# Transform to tensor
A = TF.to_tensor(A)
B = TF.to_tensor(B)
# Normalize
normalize = transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
A = normalize(A)
B = normalize(B)
return A, B
def __getitem__(self, index):
img = Image.open(self.files[index % len(self.files)])
w, h = img.size
img_A = img.crop((0, 0, w / 2, h)) # PIL
img_B = img.crop((w / 2, 0, w, h)) # PIL
# augmented, but remains paired
img_A_aug, img_B_aug = self.aug_transform(img_A, img_B)
return { "A": img_A_aug,
"B": img_B_aug}
def __len__(self):
return len(self.files)Dataloader
Only pass the transforms_ to the MainDataset() class, since tranformations are done in-line with the AugDataset() class. We divide the batch size by 2 for each dataloader, if you want to have an even number of images for the regular and the augmented dataset. For example, if the batch size is 64, the regular dataset will load in 32 images, and the augmented will load in 32 random images. I use RandomSampler to take a random batch of 32 images from the AugDataset().
# Only for the MainDataset() no augmentations
transforms_ = [
transforms.Resize((img_height, img_width), Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
main_dataloader = DataLoader(
MainDataset(root = "iris_v3_pairs",
transforms_=transforms_,
mode="train"),
batch_size=batch_size//2,
shuffle=True,
num_workers=8,
drop_last=True,
)
random_sampler = RandomSampler(AugDataset(root = "iris_v3_pairs",
transforms_= None,
mode="train"))
aug_dataloader = DataLoader(
AugDataset(root = "iris_v3_pairs",
transforms_= None,
mode="train"),
batch_size=batch_size//2,
sampler=random_sampler,
num_workers=8,
drop_last=True,
)
Read it in
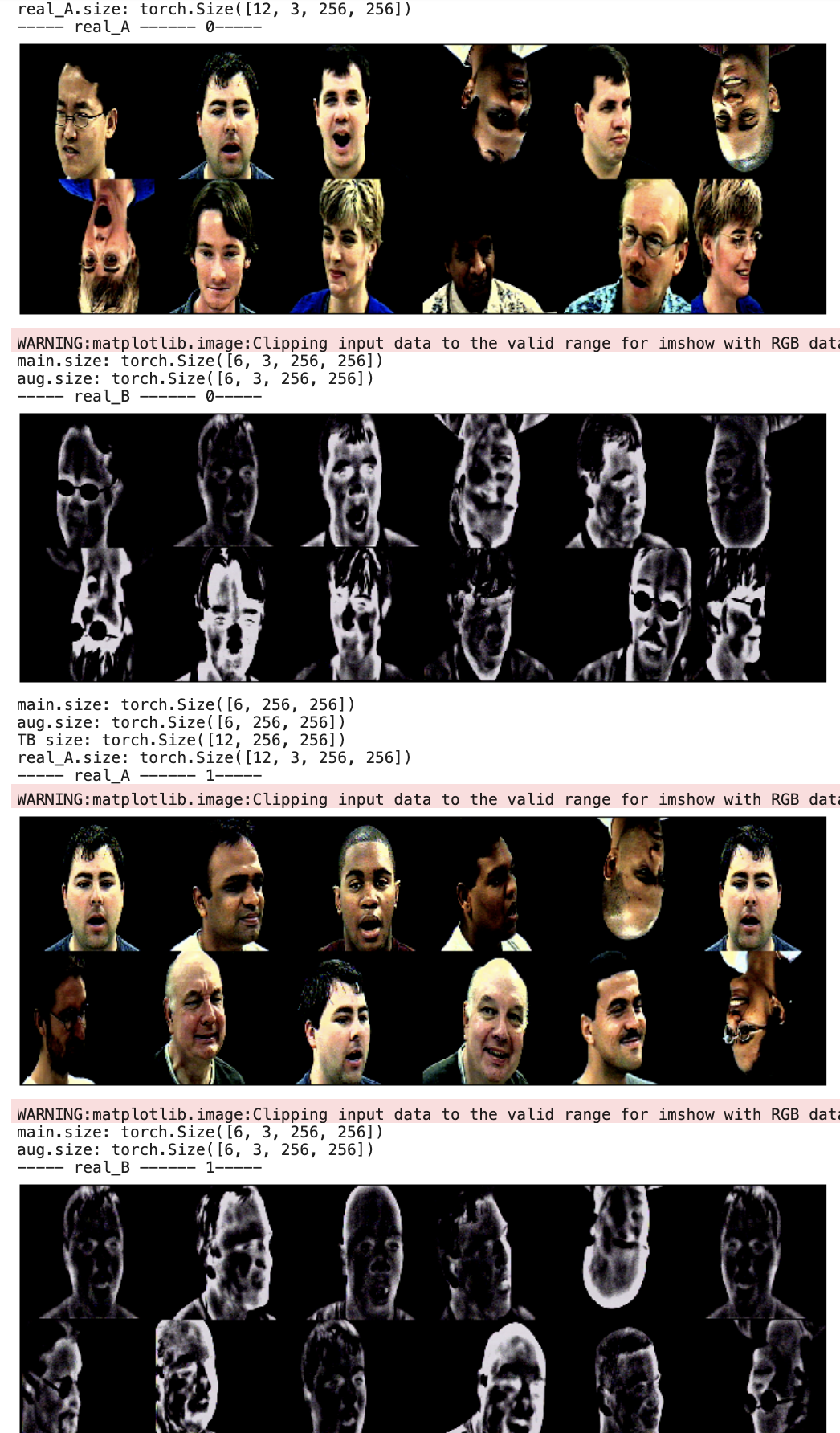
If you simply torch.cat() the regular ("main") and augmented batch, it will stay in exact order meaning, that there will be a batch of 32 images (per our previous explanation) of regular images, followed by another batch of 32 augmented images. In an effort to prevent memorization, we should randomly shuffle this across the indices. A simple torch.randperm() will suffice, and then we can store the indices as idx. Now we use the idx and pass them to a function you can use called concat_output. This will ensure the main (regular) images and augmented images stay aligned by index, as we always want the A (visible) image and B (thermal) image to stay paired, regardless of whether it's augmented or not.
for i, batch1 in enumerate(main_dataloader):
try:
aug_iterator = iter(aug_dataloader)
batch2 = next(aug_iterator)
except StopIteration:
main_iterator = iter(main_dataloader)
batch2 = next(main_iterator)
real_A_main = Variable(batch1["A"])
real_A_aug = Variable(batch2["A"])
real_A = torch.cat((real_A_main, real_A_aug), dim=0)
idx = torch.randperm(real_A.shape[0]) # change by the 0th (batches)
real_A = real_A[idx].view(real_A.size())
real_B = concat_output("B", idx)
print("----- real_A ------ {}-----".format(i))
imshow(real_A)
print("----- real_B ------ {}-----".format(i))
imshow(real_B)Use this handy function to visualize the output.
def imshow(input: torch.Tensor):
out = torchvision.utils.make_grid(input, nrow=6)
out_np: np.ndarray = K.utils.tensor_to_image(out)
plt.figure(figsize=(12,12))
plt.imshow(out_np)
plt.axis('off')
plt.show()