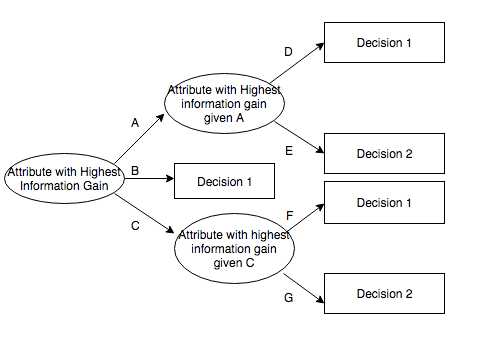
"Reinforcement learning with deep energy-based policies"


It's been a very long time since I've last posted, and at last I've come up for some air after writing a few papers and a lot of code. One thing I've come to appreciate in my PhD studies is the frequent requirement to review and present on a paper. These are usually key works in AI that I will later need to understand cold, for my comprehensive exams. In order to keep that spirit alive and also share what I've learned, I'll start to publish my reviews I've submitted to class here on my blog. I'll also open a link on my Google Drive for you to download the slides I created to present in class. The first one was actually AutoGAN, the post that's been lingering on my site forever. The second one is this - a paper review of a very important paper by Tuomas et al. Haarnoja, Tuomas, et al. "Reinforcement learning with deep energy-based policies." arXiv preprint arXiv:1702.08165 (2017). Detailed videos and explanation here at https://bair.berkeley.edu/blog/2017/10/06/soft-q-learning/
Here is the LINK to Slides (which you'll need to download, too large to open in Google directly)

Summary
This paper contributes a mathematical approach for stochastic deep reinforcement learning (RL) that was motivated by algorithms at the time (2017) that approached the search space deterministically. Specifically, this paper contributes a tractable and efficient algorithm for optimizing arbitrary multimodal stochastic policies through i) the development of a soft Q-learning method to explore multiple actions (e.g. multimodal policy distribution), ii) the inclusion of an energy-based policy to aid exploration for complex tasks, through the approximation of the Bellman optimality function as a neural network, and iii) use of a maximum entropy policy for initialization for fine-tuning that improves pretraining with random or conventional maximum reward objectives.
The current RL algorithms of the time lacked one or several of these important components for practical use – tractability, stochasticity, generative mapping (e.g. energy-based policy), improved initialization, and exploration and robustness in a multimodal landscape. The current paper demonstrates their soft Q learning approach through mathematical proofs in addition to empirical results from three different set of experiments.

The authors make a point to assert that RL training is sensitive to randomness in the environment, initialization of the policy, and the algorithm implementation. For example, two policies may be trained to optimize a deterministic reward function that encourages forward motion, but despite both policies converging, gaits of cheetah agents remain different and variational. A deterministic solution only finds one single way of accomplishing a task, opening the RL agent to vulnerability of changes in the real-world environment in the form of adversarial perturbations. Adapting and recovering from such changes currently required in 2017, the new training of RL algorithms for the specific task, from scratch. Their results are significant and important, as soft Q learning provides multiple policies used by the agent to try out all possible ways to perform the task; hence it’s stochasticity. The resulting policy can serve as a good initialization for finetuning to a more specific behavior, such as learning all the ways a robot can move forward then using the same initialization to learn how to bound, jump, and run.
Overall Approach
Their approach is based on the soft Q-function, but can be implemented via a tractable stochastic gradient descent procedure with approximate sampling. In a nutshell, the algorithms works as follows: i) Collect experience by sampling action from statetusing the sample NN (f) and save the experience in replay memory, ii) Sample a minibatch from the replay memory {s, a, r, s_{t+1}}, iii) Update the soft Q-function parameters which includes computing soft values V, computing the gradient of J, and updating theta (parameters), iv) Update the policy. Due to the intractability of using Q tables, soft Q learning uses a function approximator to estimate the Q-values by finding good parameters: $$Q(s, a; \theta) \approx Q^*(s,a)$$ In this case, the authors choose a neural network to act as the approximator: $$a_{t}{i} = f^*(\xi^i; s_t)$$ where $$\xi$$ is the exponential energy function. The current state is the input through the deep Q-neural network, and multiple Q-value actions are outputted.
Approximator
Stochasticity is introduced through modification of the standard deterministic RL policy, which is a class of RL algorithms called “maximum entropy policies”. Entropy is maximized at each visited state, where the entropy added to the objective function improves exploration by discouraging premature convergence to less than optimal deterministic policies. As such, the policy follows an EBM distribution: $$\pi(a_t | s_t) \propto exp(\xi(s_t,a_t))$$. Actions must be sampled from this policy. The neural network acts to approximate the Bellman equation: $$\epsilon(s_t, a_t) = - \frac{1}{\alpha} Q^{*}{soft}(s_t, a_t)$$ and suffices as the target network. As a result, the authors assert that soft Q learning has encouraged the model to distribute probability mass across all actions as opposed to a deterministic approach, where the mass is centered on only one action. The authors assert that soft Q learning acts as an actor in an actor-critic environment, however, no critic is offered as the opposing neural network or function approximator in the paper. The neural network approximates the energy-based distribution in terms of KL divergence, where the cost given the learned parameters and current state seek to minimize the KL divergence between the induced distribution $$\pi^\phi(a_t|s_t)$$ and $$exp(\xi(s_t, a_t))$$. For optimizing search, the authors use Stein variational gradient descent (SVGD) by Liu, et al[1] instead of MCMC.
Research Questions
Experiments were carried out to address three primary research questions:
(1) Does our soft Q-learning method accurately capture a multi-modal policy distribution?
(2) Can soft Q-learning with energy-based policies aid exploration for complex tasks that require tracking multiple modes?
(3) Can a maximum entropy policy serve as a good initialization for fine- tuning on different tasks, when compared to pretraining with a standard deterministic objective?
With regards to (1), their model in a 2D multimodal landscape demonstrated stochastic policy sampling by closely following the energy landscape, learning diverse and complex trajectories (unimodal, convex, bimodal) to reach maximum rewards, where no one single path was dominant over another and all adopted to various distributions. With regards to (2), their method was able to keep track of multiple modes (swimming and quadruple hallway exploration), where multiple agents explored various paths, but ultimately converged in both experiments. With regards to (3), compositionality was demonstrated through novel experiments where two separately trained soft Q learning policies were learned (moving a cylindrical object to a target location illustrated by red stripes (one to the far right, one directly in front)) – in order to be composed into a new policy “pretrained” to then solve the task of moving the object to the right and on the right target simultaneously. When compared to policies trained through random initialization and DDPG, soft Q learning using maximum entropy initialization outperforms learning faster.
Conclusion
The utility and practical application of their approach is intuitive and backed up by several experiments. The paper is dense and requires several read-throughs to comprehend the various theorems and concepts being used. If appropriate, a graphical figure to illustrate the connections between formulae may be instructive. But overall, the organization of the work makes sense, providing motivation up front, explicit overviews of experiments, and proofs in the back. Some mathematic principles, however, may need to be more explicitly defined in plain language to include the utility of SVGD, the Bellman backup, Bellman error, and the overall stochastic optimization of Qsoft. The paper builds on the then, burgeoning field of deep RL, by Mnih et al[2], Silver et al[3], Lillicrap[4], Ziebert[5], and Z-learning by Todorov[6]. But the original of this work is significant in their ability to offer a tractable solution through EBMs, function approximation, and soft Bellman optimization using the SVGD.
References:
[1] Liu, Q. and Wang, D. Stein variational gradient descent: A general purpose bayesian inference algorithm. In Ad- vances In Neural Information Processing Systems, pp. 2370–2378, 2016.
[2] Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., and Riedmiller, M. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013
[3] Silver, D., Lever, G., Heess, N., Degris, T., Wierstra, D., and Riedmiller, M. Deterministic policy gradient algo- rithms. In Int. Conf on Machine Learning, 2014.
[4] Lillicrap, T. P., Hunt, J. J., Pritzel, A., Heess, N., Erez, T., Tassa, Y., Silver, D., and Wierstra, D. Continuous control with deep reinforcement learning. arXiv preprint arXiv:1509.02971, 2015
[5] Ziebart, B. D., Maas, A. L., Bagnell, J. A., and Dey, A. K. Maximum entropy inverse reinforcement learning. In AAAI Conference on Artificial Intelligence, pp. 1433– 1438, 2008.
[6] Todorov, E. Compositionality of optimal control laws. In Advances in Neural Information Processing Systems, pp. 1856–1864, 2009.