Survey of Object Detection

Several years ago I implemented GoogLeNet on the Jetson TX2. Since then I've been dealing with object detection problems both from a data scientist side, and also team leader side.
Finally got the #Jetsontx2 up and running this morning, using the sample video on the Tegra API. @nvidia pic.twitter.com/okCZLMmUhj
— Catherine Ordun (@nudro) June 9, 2018
There are absolutely tons of resources out there on object detection, so I'm not going to recycle some great posts and tutorials that already exist. Here's a summary of some of my personal reflections on basic object detection models, with the papers, Stanford cs231n references, and YouTube videos for entertainment. A summary of R-CNN, Fast R-CNN, Faster R-CNN, with "basic steps" how each one evolved over the years. At the end, we review YOLO and SSD. Mean Average Precision is provided for each at the very end of this post.
| Basic Steps | R-CNN (2014) | Fast R-CNN (2015) | Faster R-CNN (2015) |
|---|---|---|---|
| Tag Line | Use a CNN per region | Single stage loss using a deep network | Introducing the Region Proposal Network |
| 1 | Selective Search yields n=2000 ROIs | Apply backbone like AlexNet to yield feature map | Apply backbone like AlexNet to yield feature map |
| 2 | Warp regions | ROI Pooling on features | Region Proposal Network |
| 3 | CNN per region | Apply FC layers from backboone to each region | Stage 1 Loss - RPN classification for anchor box, RPN regression transform for bbox |
| 4 | Category (softmax) and bbox transform (L2) | Category (softmax) and bbox - Logloss and Smooth L1 for multitask-loss | Stage 2 Loss - Object classification proposals (background or object), predict trransform from propsoal box to object box |
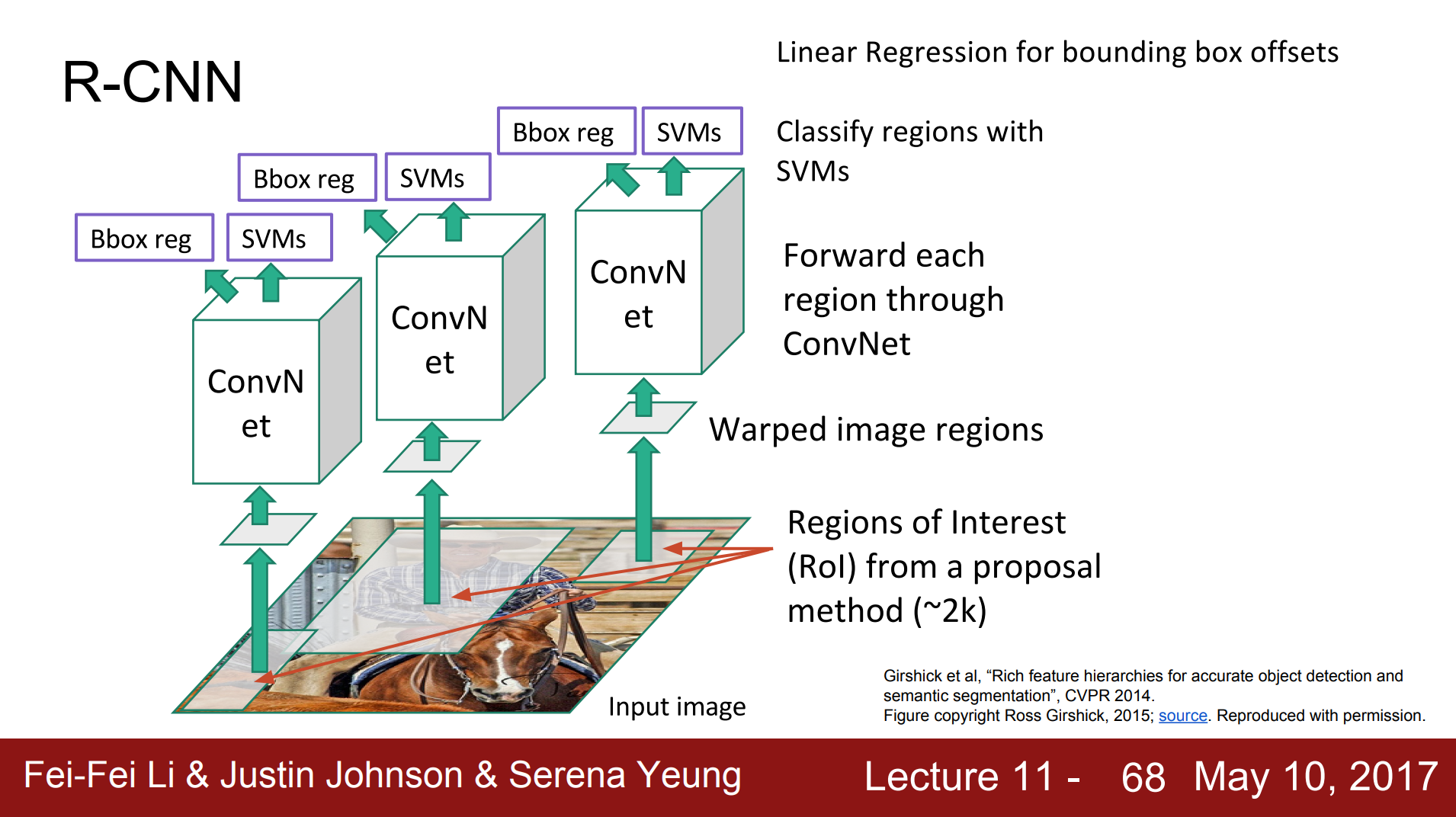
R-CNN, 2014, Girschick, et al.
"To what extent do the CNN classification results on ImageNet generalize to object detection results on the PASCAL VOC Challenge? We answer this question decisively by bridging the chasm between image classification and object detection. This paper is the first to show that a CNN can lead to dramatically higher object detection performance on PASCAL VOC as compared to systems based on simpler HOG-like features. Achieving this result required solving two problems: localizing objects with a deep network and training a high-capacity model with only a small quantity of annotated detection data."
Paper - Girshick, Ross, et al. "Rich feature hierarchies for accurate object detection and semantic segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2014.
Diagram courtesy CS231n:
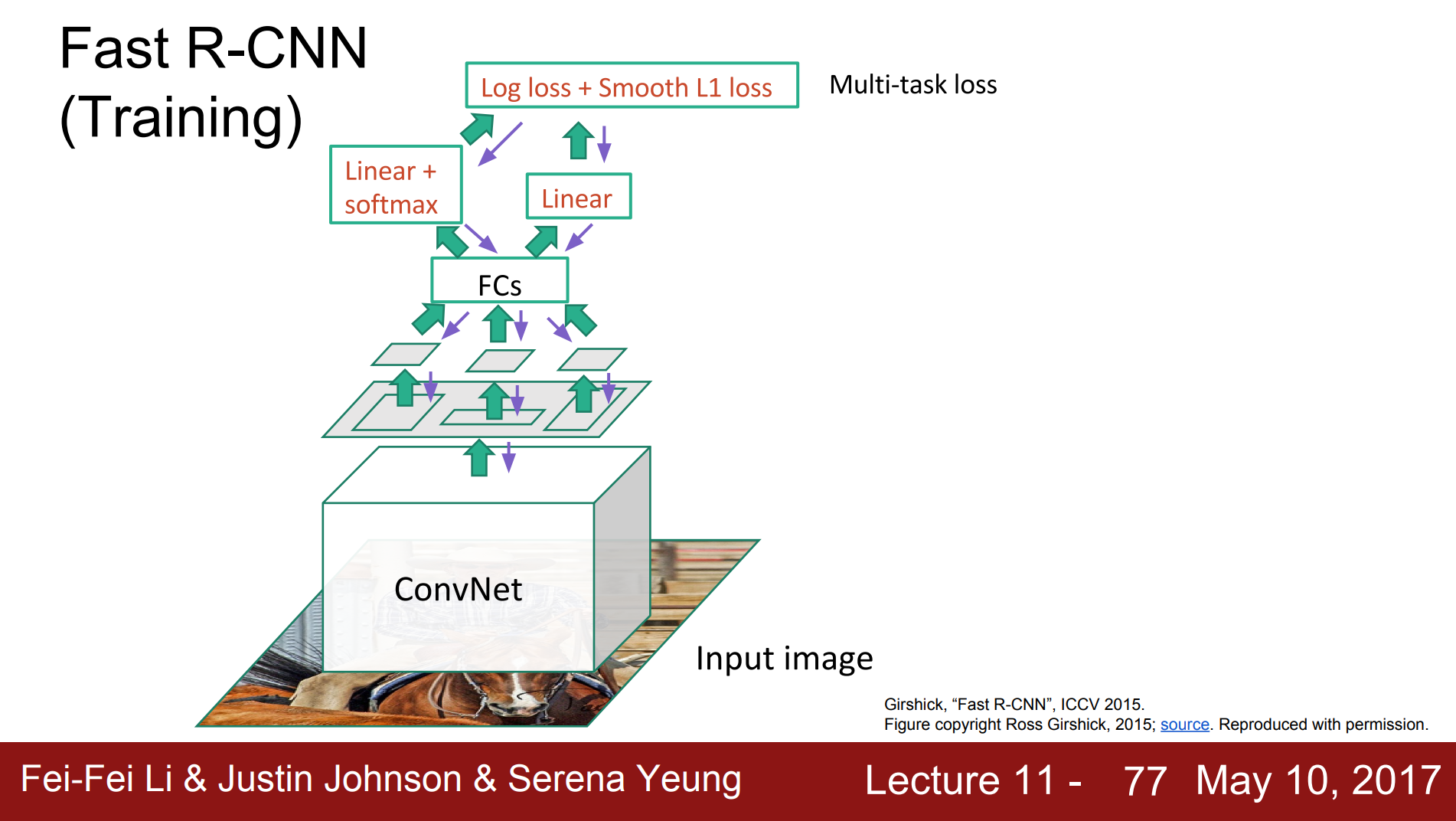
Fast R-CNN, 2015, Girschick
"Complexity arises because detection requires the accurate localization of objects, creating two primary challenges. First, numerous candidate object locations (often called “proposals”) must be processed. Second, these candidates provide only rough localization that must be refined to achieve precise localization. Solutions to these problems often compromise speed, accuracy, or simplicity."
"A Fast R-CNN network takes as input an entire image and a set of object proposals. The network first processes the whole image with several convolutional (conv) and max pooling layers to produce a conv feature map."
Paper - Girshick, Ross. "Fast r-cnn." Proceedings of the IEEE international conference on computer vision. 2015.
Diagram courtesy CS231n:
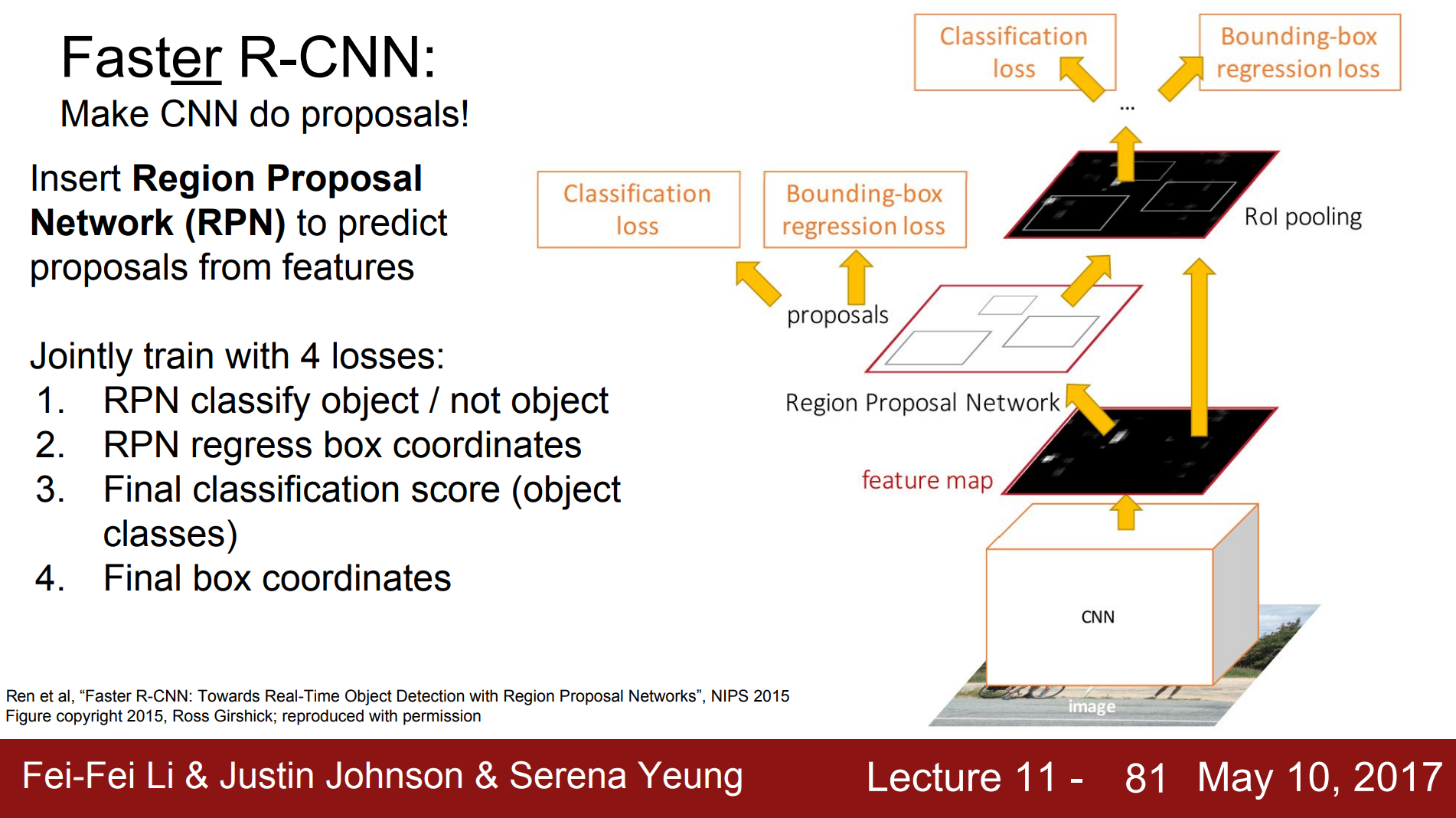
Faster R-CNN, 2015, Ren, et al.
The problem it solves to improve using Selective Search from Fast R-CNN:
"Yet when compared to efficient detection networks [2], Selective Search is an order of magnitude slower, at 2 seconds per image in a CPU implementation."
"Our observation is that the convolutional feature maps used by region-based detectors, like Fast RCNN, can also be used for generating region proposals. On top of these convolutional features, we construct an RPN by adding a few additional convolutional layers that simultaneously regress region bounds and object scores at each location on a regular grid."
Paper: Ren, Shaoqing, et al. "Faster r-cnn: Towards real-time object detection with region proposal networks." Advances in neural information processing systems. 2015.
Diagram courtesy CS231n:
Single Search - YOLO, Redmon, et al.
Paper - Redmon, Joseph, et al. "You only look once: Unified, real-time object detection." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
Damn, Joseph.
"Fast and Faster R-CNN focus on speeding up the R-CNN framework by sharing computation and using neural networks to propose regions instead of Selective Search [14] [27]. While they offer speed and accuracy improvements over R-CNN, both still fall short of real-time performance ...Instead of trying to optimize individual components of a large detection pipeline, YOLO throws out the pipeline entirely and is fast by design."
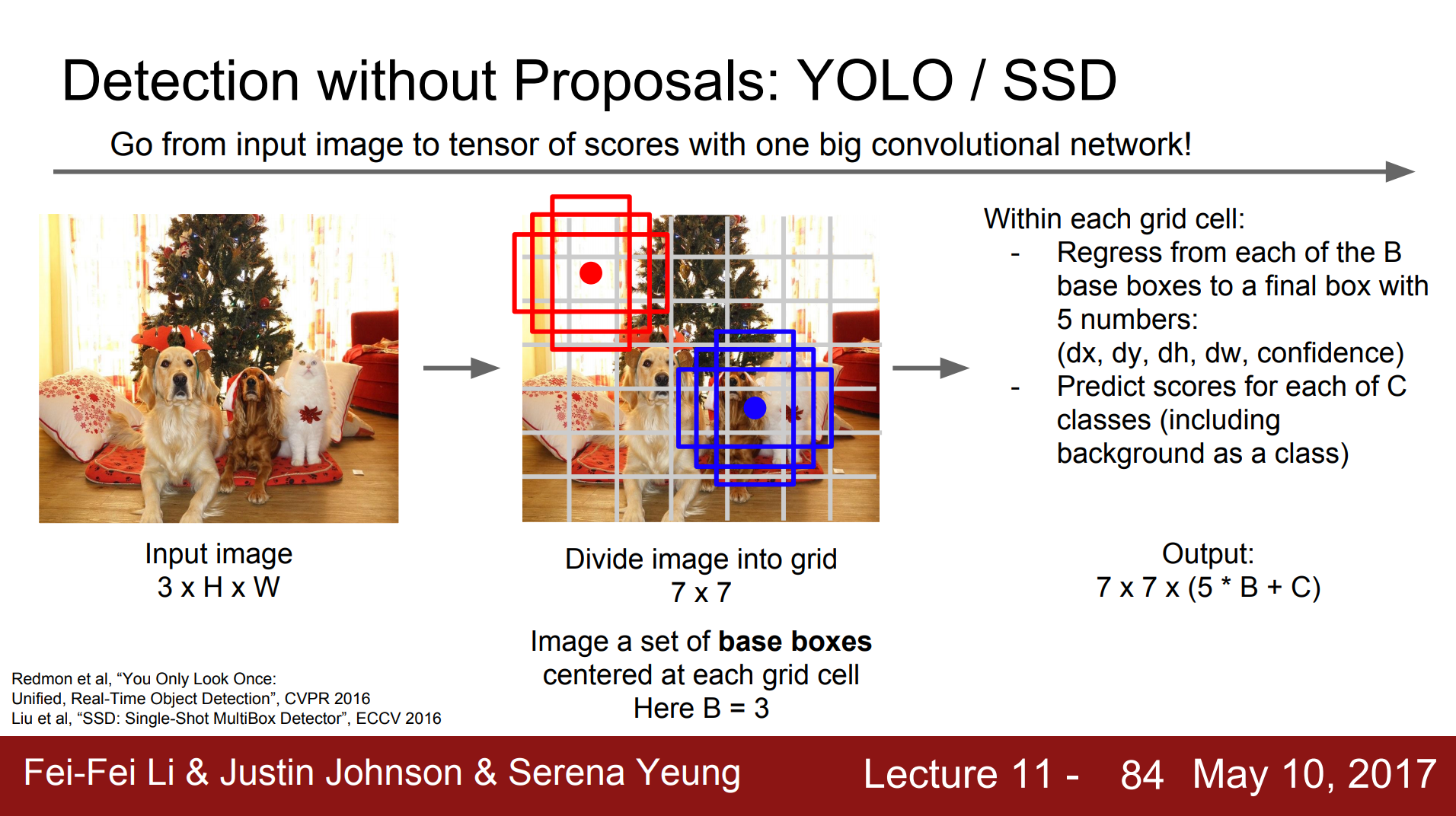
In YOLO, the input image is divided into an S × S grid. The final fully connected layer of a GoogLeNet network (later, YOLOV2 uses Darknet-19), predicts both the class probabilities and the bounding box coordinates. It uses sum-squared error that weights errors in large and small boxes. YOLO regresses each of the B-base boxes to a final box with 5 numbers outputted: (dx, dy, dh, dw, confidence). The 5th number, the "confidence score" comes from how each grid cell also predicted C conditional class probabilities, Pr(Classi |Object):

Single Shot - SSD, 2016, Liu et al.
Paper - Liu, Wei, et al. "Ssd: Single shot multibox detector." European conference on computer vision. Springer, Cham, 2016.
"The SSD approach is based on a feed-forward convolutional network that produces a fixed-size collection of bounding boxes and scores for the presence of object class instances in those boxes, followed by a non-maximum suppression step to produce the final detections."
"We add convolutional feature layers to the end of the truncated base network. These layers decrease in size progressively and allow predictions of detections at multiple scales."
SSD can detect objects in one pass at different scales, without requiring the input image to be rescaled separately each time. SSD's minimizes a multibox loss similar to previous object detectors. Overall loss function is a weighted sum of the localization loss (loc) (smooth L1) and the confidence loss (conf) (softmax).
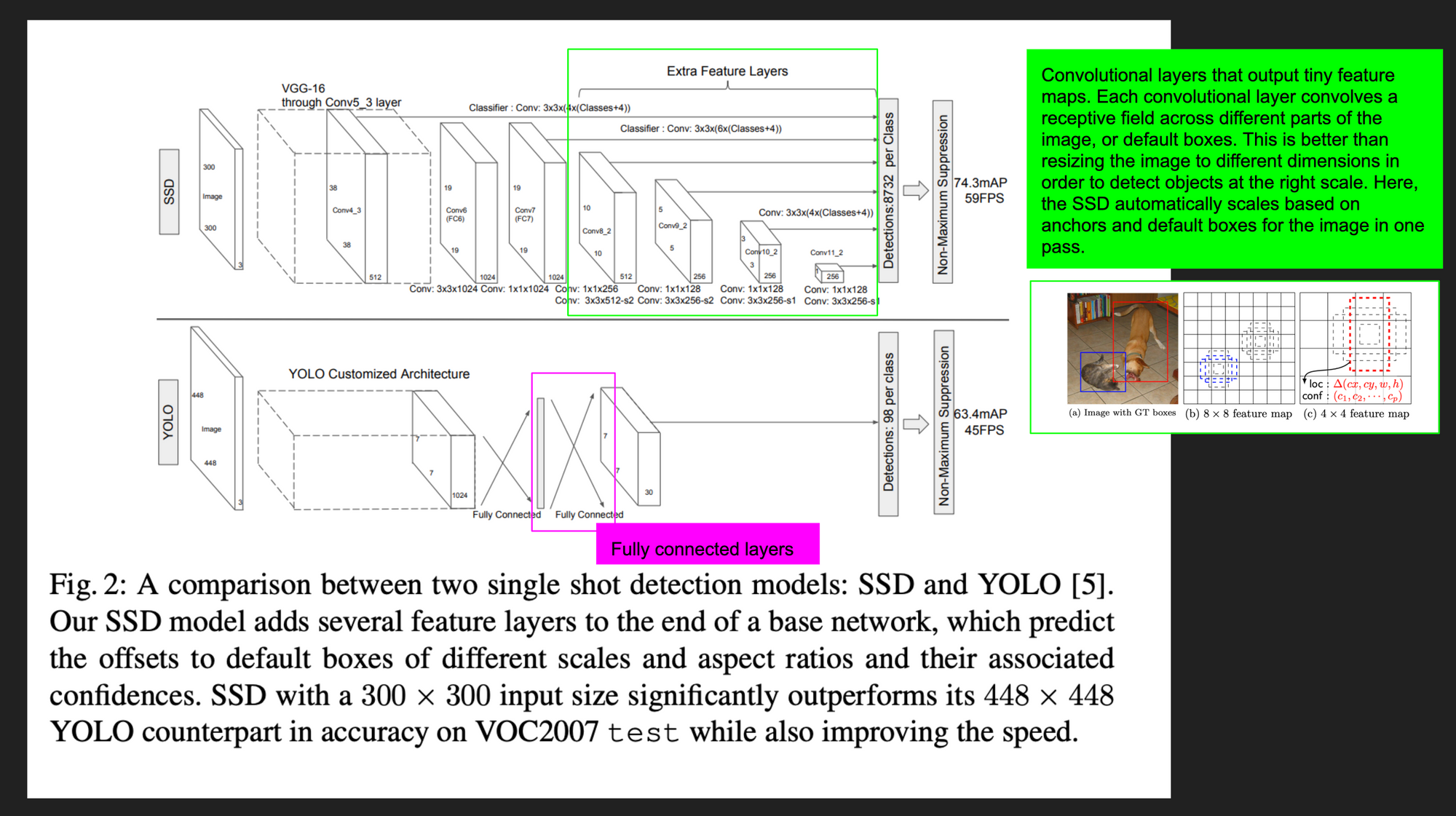
Critics of YOLO and SSD argue that both networks sacrifice speed at the cost of accuracy (mean average precision). Both YOLO and SSD aim to be fast on object detection on full motion video:
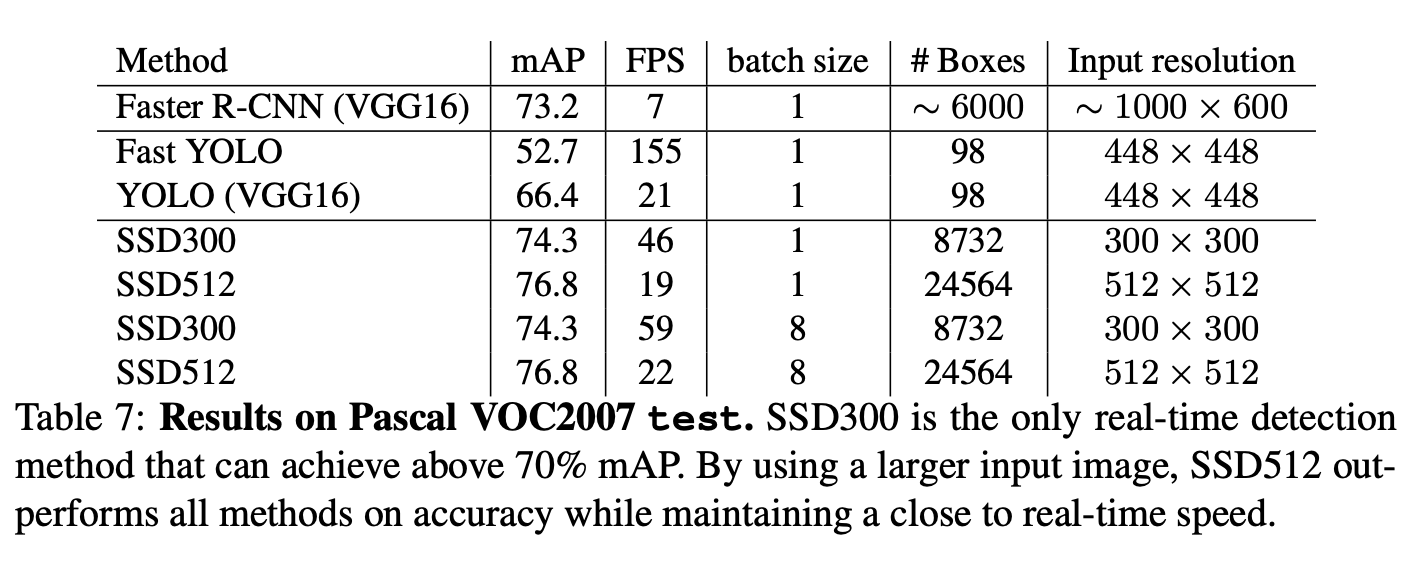
Mean Average Precision for Object Detection Models
Taken from each model's respective papers in the links above.
| Object Detection Model | R-CNN (2014) | Fast R-CNN | Faster R-CNN | YOLO | SSD |
|---|---|---|---|---|---|
| PASCAL 2012 mAP | 62% | 66% | 70.4% | 73.4% (YOLOV2) | 80.0% (SSD512) |