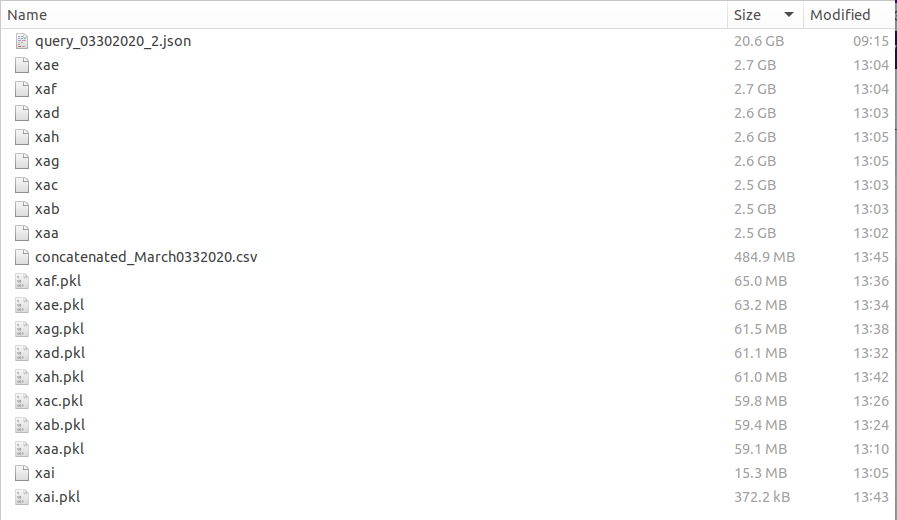
bash to split .json

Let's split up a 20.3 GB .json file of Twitter data consisting of 2,802,069 tweets.
There are a variety of platforms and systems out there to handle "big data". From DataBricks Spark to Azure, to all sorts of both proprietary and free systems to deal with lots and lots of records. I think that I'm right on the cusp, and as a result, I sought to merely take a simpler approach of splitting up my dataset into batches to work with.
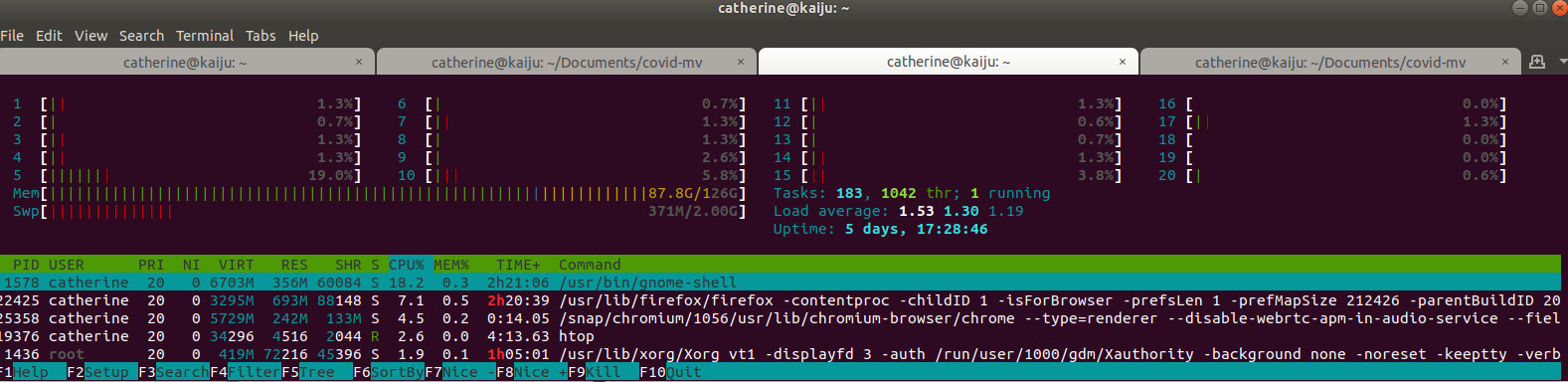
If you're on Ubuntu like me, I'd recommend sudo snap install htop in order to install a handy memory monitor. If you do scratch work in Jupyter like I do, you can see how much Mem and Swp you're consuming in some of these processes. You can also kill a PID if something becomes responsive.
Twitter Data
Using tweepy and an individual user account to Twitter, I streamed several million tweets overnight. We end up with a .json file with these fields:
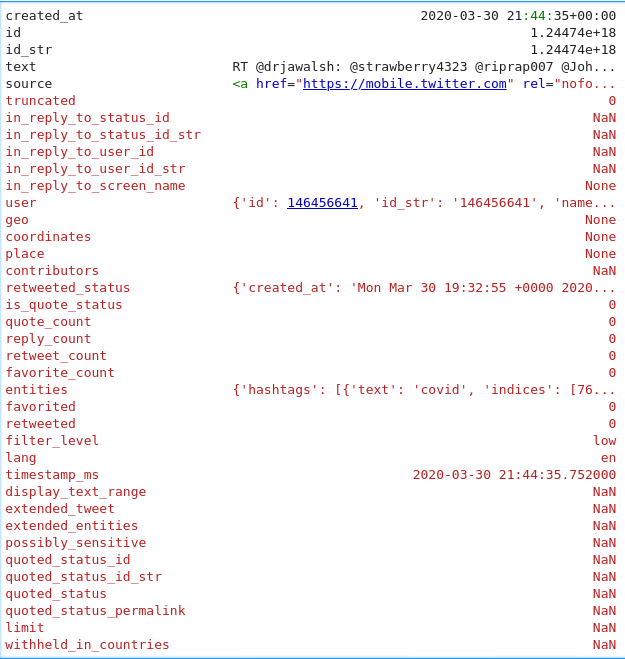
For my analysis, all I need is the created_at and text fields. We can ignore everything else for now. I used this as a reference:
 John D K
John D K
Let's start by figuring out how many lines/tweets we have in our giant file called query_03302020_1.json. We have 2,802,069 tweets. Based on this, if I slice this up into files of 350,000 tweets, this will lead to 9 separate data files. Note, that the 9th file will have only 2069 tweets.
catherine@kaiju:~/Documents/covid-mv$ wc -l query_03302020_2.json
>>2802069 query_03302020_2.json
catherine@kaiju:~/Documents/covid-mv$ split -l 350000 query_03302020_2.json
You'll end up with default data files without extensions, named:
xaa
xab
xac
xad
xae
xaf
xag
xah
xai
Pickle them so you can read in as a dataframe:
def drop_and_pickle(path):
#json is a path in quotes
with open(path) as f:
df = pd.DataFrame(json.loads(line) for line in f)
df = df.drop(['id', 'id_str', 'source', 'truncated',
'in_reply_to_status_id', 'in_reply_to_status_id_str',
'in_reply_to_user_id', 'in_reply_to_user_id_str',
'in_reply_to_screen_name', 'user', 'geo', 'contributors',
'retweeted_status', 'is_quote_status', 'quote_count',
'reply_count', 'retweet_count', 'favorite_count', 'entities',
'favorited', 'retweeted', 'filter_level', 'lang',
'timestamp_ms', 'display_text_range', 'extended_tweet',
'extended_entities', 'possibly_sensitive',
'quoted_status_id','quoted_status_id_str', 'quoted_status',
'quoted_status_permalink', 'limit', 'withheld_in_countries'],
axis=1)
df.to_pickle("{}.pkl".format(str(path))) #change file name
Now read each file in as a .pkl file and concatenate as a pandas dataframe.
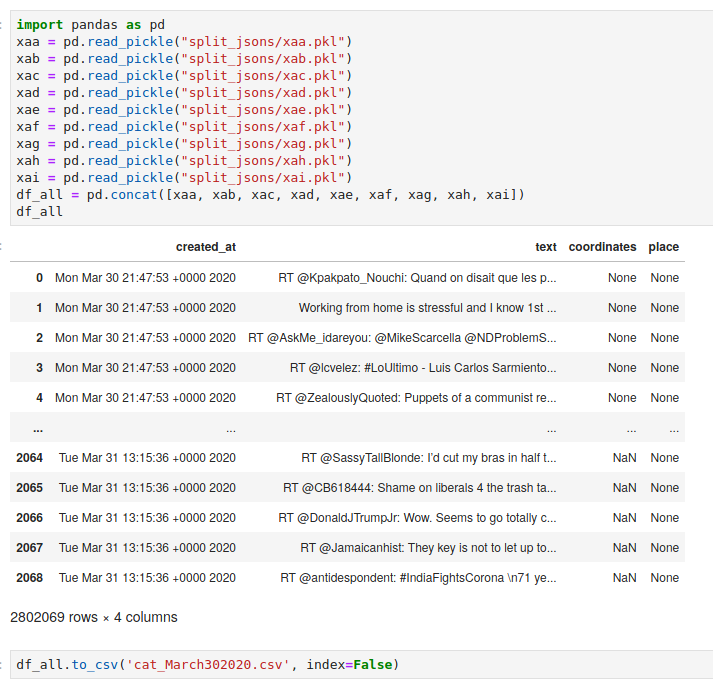
To give you a sense of the reduced size of the files, also enabled by dropping columns we didn't need:
We went from a 20.6 GB json file -> bash generated data files of 15.3 MB (remember the file with only 2069 tweets) to 2.7 GB, each -> pkl files 372 kB to 65 MB -> a final pandas dataframe of 484.9 MB that I can totally work with moving forward. You'll also see that the split of the jsons, preserves the sequence of the files.