Pandas and PIL

This was a quick and handy little script that I think some of you might need from time to time, especially if you're dealing with lots and lots of annotated, labeled images. In the AffectNet dataset, there's a 5.4 Gb file that for me on Ubuntu 18.04, I need to unrar. Unrar'ing is kinda relaxing to watch...
Anyway, there's about 420,000 images, each with a .csv file with this kind of metadata that correspond to images like the below. That guy below looks like he got caught stealing a candy bar. I digress...
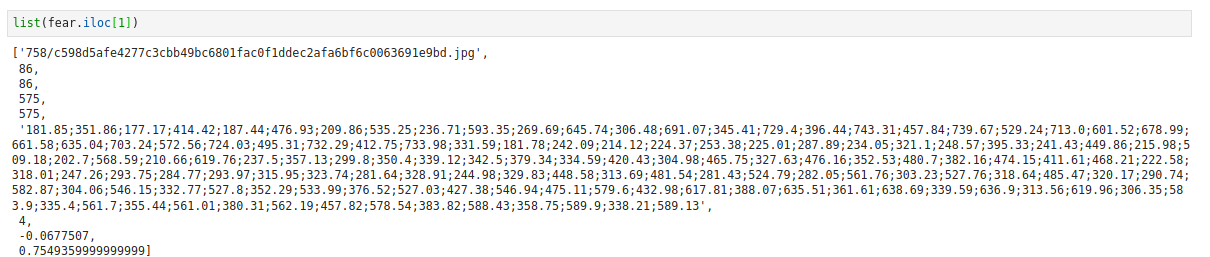


Of which we can nicely read into a dataframe and sort it by, in my case, the expression type == 4. I created a df called "fear" which is the expression for expression type 4.

So, now here's the script that we can iterate through each row of the dataframe, in this case subDirectory_filePath, and save the images specific to that file, over to a new target directory.
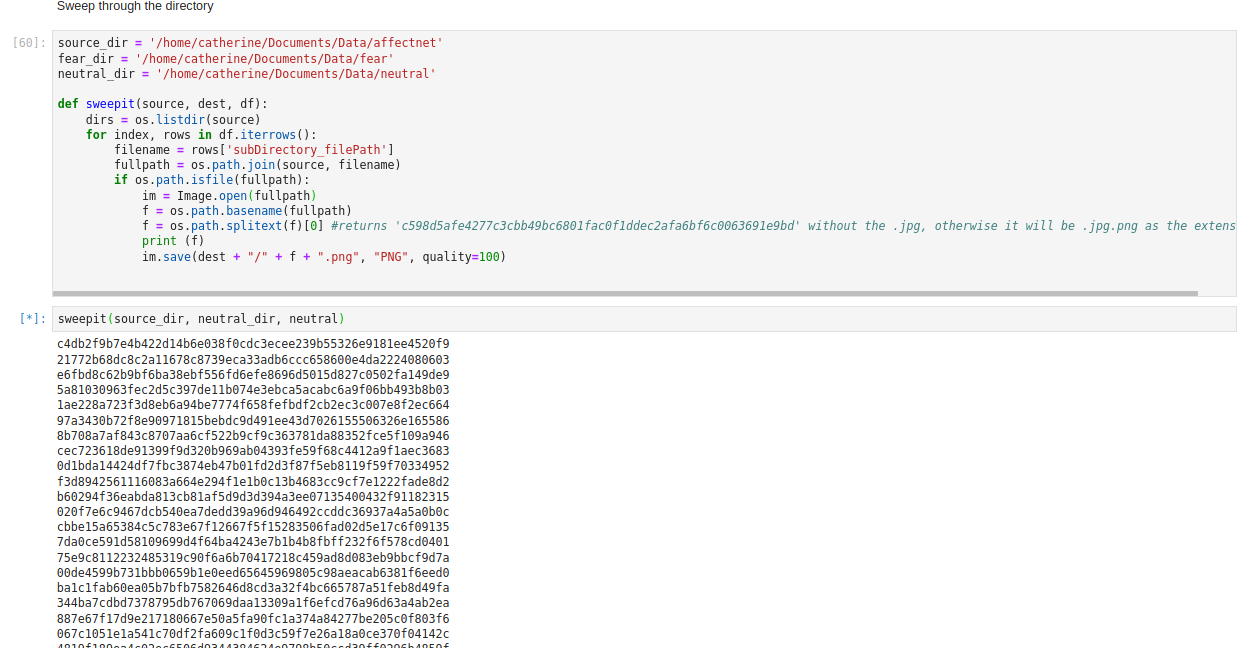
source_dir = '/home/catherine/Documents/Data/affectnet'
fear_dir = '/home/catherine/Documents/Data/fear'
neutral_dir = '/home/catherine/Documents/Data/neutral'
def sweepit(source, dest, df):
dirs = os.listdir(source)for index, rows in df.iterrows():
filename = rows['subDirectory_filePath']
fullpath = os.path.join(source, filename)
if os.path.isfile(fullpath):
im = Image.open(fullpath)
f = os.path.basename(fullpath)
f = os.path.splitext(f)[0]
print (f)
im.save(dest + "/" + f + ".png", "PNG", quality=100)
It's an important trick to understand how os.path works with regards to os.path.basename and os.path.splitext. This is a detail to help you ensure that you only save to the destination directory the file name without the extension, and the filename without the parent directory. See: https://stackoverflow.com/questions/678236/how-to-get-the-filename-without-the-extension-from-a-path-in-python
For example:
fullpath = '/home/catherine/Documents/Data/affectnet/664/7bfb78ea4f9b9c267d74133421fbe5a7261fec6dd89cd4a730a39e69.jpg'
f = os.path.basename(fullpath)
returns the string after 664/
'7bfb78ea4f9b9c267d74133421fbe5a7261fec6dd89cd4a730a39e69.jpg'
f = os.path.splittext(f)[0]
returns the string without the .jpg extension
7bfb78ea4f9b9c267d74133421fbe5a7261fec6dd89cd4a730a39e69
You may want to add %timeit at the start of the cell to see how long it takes. For me, I had 6378 images, and on my i9 processor it took about 10 minutes.