Keras Leaderboard from Strata AI

Back in April 2019, I gave a presentation at Strata AI on a prototype API to track model development metadata for reproducibility using a simple 3-layer 2D CNN for a basic image classification task. I was planning to submit this short proceedings paper to CMU AIDR later in the summer, but missed the deadline. Below is the short paper and the link to my Github repo. All pull requests welcome!
Introduction
Data scientists rely on open source deep learning frameworks for building neural network algorithms. As data scientists develop models, they often lose track of how networks were designed, how the data was processed, and what the results were, leading to difficulties in reproducing results. We offer a basic API using existing functionality of the popular deep learning framework, Keras, that can be used to improve the organization and tracking of metadata during model development. This paper discusses the value of metadata and offers an example architecture that can be used to develop a custom model tracking API in Keras. Our code is made publicly available at https://github.com/nudro/keras_leaderboard.
As data scientists develop experiments and build models, they quickly lose track of the algorithms they design, much less develop a systematic and organized way to track data transformations, model hyper-parameters, components of each layer, model accuracy, classification metrics, and gradients. Multiple papers as discussed in Section 2, and variety of blogs cite anecdotal evidence about the struggles data scientists have with managing the volume of metadata [1]. Recently commercial frameworks such as the Amazon Web Services SageMaker platform, Comet ML, DataBricks, DataRobot, and H2O Driverless AI offer powerful systems to manage metadata including data transformations, model design, tuning, evaluation metrics, and deployment measures across multiple machine learning models simultaneously.
This paper argues that many basic metadata tracking features available in proprietary systems are readily available through a combination of Python programming and through simple API calls in open source deep learning frameworks. We introduce a prototype demonstrating simple functionality intrinsic to the Keras API to extract metadata. Keras is the second most popular deep learning framework according to a 2018 analysis by Jeff Hale based on Online job listings, KDnuggets usage survey, Google search volume, Medium.com articles, Amazon books, ArXiv articles, and GitHub Activity following TensorFlow [2]. Its popularity is largely due to its “API designed for human beings, not machines” meaning its user-friendly API, modularity of developing deep learning models, easy extensibility, and implementation in Python [3]. Thousands of data scientists across the world use Keras for prototyping due to the ease of syntax and ability to quickly learn how to use the sequential and functional APIs.
Metadata elements include network configurations of model layers, hyperparameters, training parameters, evaluation metrics, and prediction metadata, in addition to information about data transformations and preprocessing. We introduce an API schema to extract metadata using five Python packages including Keras.
We developed this as a “starter API” for data scientists to develop their own model tracking leaderboard in an extensible manner without depending on external commercial services. This has benefits in cases where the data scientist’s code and/or data may be restricted or proprietary. Our API can also give a kick start in the data scientist’s arsenal of experimentation code to begin tracking metadata prior to the acquisition of a commercial tool or as a means to reduce the overall cost of commercial implementation. Our API is available publicly on Github and we welcome contributions and pull requests not only to improve Keras functionality but also to adopt other frameworks like PyTorch.
First, we review the value in tracking metadata that motivates our approach in Section 2. The resulting API we design to alleviate the problem is presented in Section 3, followed by examples of how to implement the API in Section 4, and opportunities for expansion and our conclusions in Section 5.
Value of MetaData
Metadata is important for deep learning model reproducibility, comparability, and workflow management across several experimental iterations of model development. Simply communicating the accuracy score of one model against another fails to convey the true differences or similarities of each model. While two convolutional neural networks (CNN) may output similar accuracies, say 0.98, the data scientist must be able to retrieve (and reproduce) the fact that one network may be a three-layer custom implementation and trained on 70% of the data while the other is a pre-trained neural network such as VGG16 and trained on 80% of the data, demonstrating that both models are indeed different and subject to different constraints such as the ease of deployment based on size of parameters.Keeping track of metadata is fairly straightforward when developing two models like the ones previously mentioned, through the use of markdown in Jupyter Notebooks, documentation in Python scripts, and even spreadsheets, PowerPoint files, or writing Python lists to file. However, as more data scientists begin to experiment and develop their own customized implementations, the variety of models can change dramatically and subsequently the metadata that is generated. Simple markdown no longer does the job and does nothing to alleviate the time it takes to manually update notes for every model tried.
Researchers argue that data scientists “have no means of tracking previously-built models or insights from previous experimentation. Consequently, the data scientist had [sic] to remember relevant information about previous models to inform the design of the next set of models” across hundreds of models in any given experiment [3]. The model data management community emphasizes the need to store and manage experimentation data and artifacts in a standard process, as opposed to a more on the fly ad-hoc style that many data scientists are accustomed to. As a result, tracking model development is an iterative and ad-hoc process [4, 5, 6]. It consists of capturing metadata about the datasets, models, prediction, evaluation, and training runs in order to improve how data scientists can compare model results, repeat experiments, and monitor progress and answer questions like:
Further, in metadata management no single entity such as a system or person has the complete view of the end-to-end machine learning lifecycle of pipeline development, training, and inference [6]. This leads to problems of missed opportunities for increased productivity, performance and robustness [6]. This problem has led to a “reproducibility crisis” where researchers are unable to replicate results from deep learning publications [7]. In a survey of 400 algorithms presented in papers at two top Artificial Intelligence (AI) conferences in recent years, only 6% of the presenters shared their source code, one third shared their test dataset, and half shared pseudocode [7]. Further, researchers demonstrated that the algorithm performance is highly sensitive not only to exact code syntax, but to random weight initialization, and to hyperparameters [7]. The AI community has responded with a variety of open source tools ranging from journals that focus on replication, methods that scan research publications, and centralized repositories for repeatable algorithms and datasets [7]. There are also several experimental open source packages like DVC [8] and Datmo [9], and commercial machine learning platforms that store and track of metadata that is generated for each experiment. All these efforts provide a degree of auditability and reproducibility that does not exist in a consistent standard across industry today.
API Schema
For this prototype API, we scope our examples to metadata generated during the development of a convolutional neural network (CNN). The metadata generated from the experiments to train a three-layer convolutional neural network and through transfer learning using frozen weights from ImageNet on a VGG-16 backbone are the two types of CNNs we use for the API prototype. Metadata that is generated from the model development pipeline is used to compare and contrast models, and sometimes used to populate visual tables like a leaderboard to rank accuracy of models. Types of metadata elements include:
Our prototype API outputs metadata elements shown. in Figure 1 that indicates the metadata and the corresponding outputs.
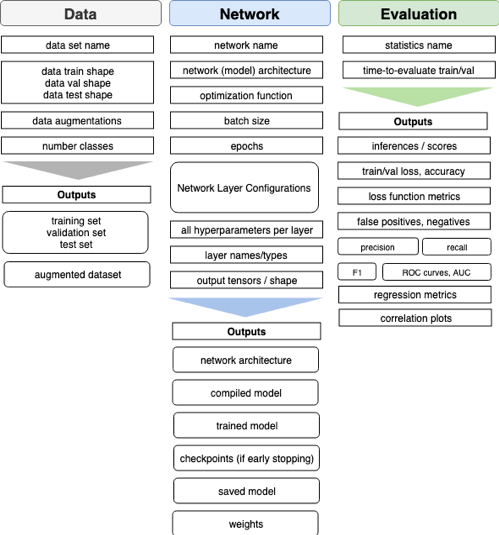
Our API is collection of Python classes that outputs metadata across the model development pipeline. Five primary Python packages are used in the API including Keras 2.2.2, pandas 0.2.3, numpy 1.14.3, scikit-learn 0.20.3, and an interactive table widget called “Qwidget” by Quantopian [10]. Figure 2 shows five object classes in the primary script called “Keras_Leaderboard”: 1) Register_Data, 2) Build_Model, 3) Fit_Model, 4) Model_Metrics, and 5) Model_Outputs. The “Run_Leaderboard” script inherits from the classes in “Keras_Leaderboard” and automates the pipeline to register the data, compile, train, evaluate, and output the model configurations.
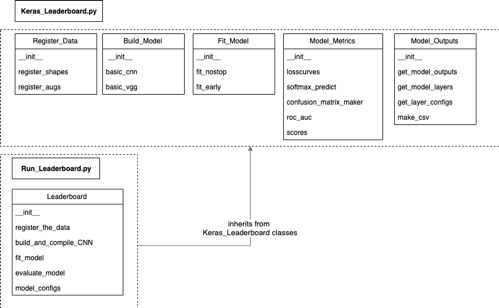
The prototype CNNs previously described are declared as Python objects in a “main.py” program that calls “Run_Leaderboard”, which in turn called “Keras_Leaderboard”. That allows us to instantiate an object and pass to it, various arguments starting with the data. This includes creating a custom name for the dataset, storing the shape and size of the training and validation tensors, and storing any augmentations of the image dataset as a dict data structure. The object can also accept the width, height, channels, optimizer, loss, metric for accuracy, number of classes, batch_size, epochs, patience (for early stopping), a custom network name, and the name for the log file of the history of the training and validation accuracy and losses. The object may be instantiated as follows:
basic_cnn_object = run_leaderboard.make_leaderboard(**args)
basic_cnn_object.register_the_data()
basic_cnn_object.build_and_compile_CNN(model_type=’cnn’)
basic_cnn_object.fit_model(**args, fit_type = “nostop”)
basic_cnn_object.model_configs(**args)
vgg_object = run_leaderboard.make_leaderboard(**args)
vgg_object.register_the_data()
vgg_object.build_and_compile_CNN(model_type=’vgg’)
vgg_object.fit_model(**args, fit_type=’fit_early’)
vgg_object.evaluate_model(**args)
vgg_object.model_configs(**args)
The output of each object is a pandas dataframe that stores the metadata. The leaderboard is generated by concatenating multiple pandas dataframes together for each model object. In the example below, the user can develop ‘k’ number of models, that outputs a respective dataframe, which is then concatenated together into a single dataframe and saved as a .csv file or generated as a widget in Jupyter Notebook.
Implementation
We demonstrate how our approach can aid practitioners using the Kaggle Art Images Dataset [11] which consists of five classes: 1) Drawings, 2) Watercolor, 3) Painting, 4) Sculpture, 5) Graphic Art, and 6) Iconography. The training set consists of 7721 RGB images and the validation set consisted of 856 RGB images that we reshaped to 100 x 100. Our data augmentations are declared as the variable “my_augs” and consist of (featurewise_center=True, featurewise_std_normalization=True, rotation_range=90, width_shift_range=0.1, height_shift_range=0.1, zoom_range=0.2).
The “basic_cnn” consists of three convolutional 2D layers: layer1 (32 filters, strides=(5,5), activation=’relu’), layer2 (64 filters, strides = (5, 5), activation = ‘relu’), layer3 (128 filters, strides=(5,5), activation =’relu’), each layer followed by MaxPooling2D layers of pool_size = 2, strides = 2. The Keras Dense (fully connected) layer consists of 64 units, followed by Dropout of 0.3, and a Dense (5 units) layer with softmax activation. The “vgg_cnn” uses as a base layer, VGG16 architecture [12] and ImageNet as weights, followed by two dense layers (256 units, 120 units), each with ‘relu’ activation, and followed by a Dense (5 units) layer with softmax activation.
We pass the following arguments to the “basic_cnn” and “vgg_cnn” objects where the user can declare their chosen optimizer (i.e. ‘sgd’ or ‘adam’), loss (‘e.g. categorical_crossentropy’), metrics (e.g. ‘accuracy’), batch_size (i.e. 2, 4, 32, or 64), epochs (i.e. 5, 10, 20, 30, or 50), patience (e.g. 3):
As a series of simple examples, one can run experiments using different model arguments such as the batch_size, number of epochs, and optimizer shown in the arguments below.
cnn1 = make_cnns(32, 5, 'adam')
cnn2 = make_cnns(4, 10, 'sgd')
cnn3 = make_cnns(2, 20, 'sgd')
cnn4 = make_cnns(32, 20, 'sgd')
cnn5 = make_cnns(64, 30, 'adam')
cnn6 = make_cnns(64, 50, 'adagrad')
vgg1 = make_vggs(32, 5, 'adam')
vgg2 = make_cnns(64, 10, 'sgd')
vgg3 = make_vggs(32, 15, 'adam')
vgg4 = make_vggs(32, 20, 'adagrad')
vgg5 = make_vggs(32, 30, 'adam')
vgg6 = make_vggs(32, 50, 'adam')
Because we pass our arguments when we instantiate the model object, the following metadata from vgg6 is populated into a dataframe and outputted:
The Quantopian QWidget can be visualized in a Jupyter Notebook and used as a Javascript-enabled table that can filtered based on the model accuracy, mean precision and mean recall in order to rank the highest scoring model out of the twelve developed. The history of the training and validation accuracy and loss files are saved in a directory specific to each experiment, along with their corresponding ROC plots and confusion matrices in .png format.
Conclusions
This is a prototype API, and as a result, has limited functionality in a production or large-scale use case. We demonstrate the ability to use Python objects as a means to pass arguments through a pipeline starting with registering the data to evaluating the model performance. We recommend contributing to the Github repository to enhance the functionality of the API including:
The logic of the API schema allows for any open source deep learning framework to be used, besides Keras. In some cases, it may be easier to extract metadata using other frameworks. For example, PyTorch offers gradients in a single line of code through its single ‘x.grad’ command, whereas extracting gradients in Keras requires use of the Keras (K) backend taking several extra steps with ‘K.sum’, ‘K.gradients’, and ‘K.function’. It would be valuable to compare the ease of extracting metadata between the Keras and PyTorch frameworks and offer both publicly as tools for model tracking and metadata management.
Acknowldgements
The authors would like to acknowledge Michael Fagundo, Joshua Luxton, and Chao Wu for their support in code review for the Github repository.
References
[1] Pete Warden (2018). Pete Warden’s blog, March 19, 2018. The Machine Learning Reproducibility Crisis. https://petewarden.com/2018/03/19/the-machine-learning-reproducibility-crisis/
[2] Jeff Hale (2018). Deep Learning Framework Power Scores 2018. https://towardsdatascience.com/deep-learning-framework-power-scores-2018-23607ddf297a
[3] https://keras.io
[4] Vartak, Manasi, et al. "M odel DB: a system for machine learning model management." Proceedings of the Workshop on Human-In-the-Loop Data Analytics. ACM, 2016.
[5] Sebastian Schelter (2018). Declarative Metadata Management: A Missing Piece in End-to-End Machine Learning. SysML Conference.
[6] Rolando Garcia (2018). Context: The missing piece in the machine learning lifecycle. KDD CMI Workshop. Vol. 114.
[7] Hutson, Matthew. "Artificial intelligence faces reproducibility crisis." (2018): 725-726.
[8] https://dvc.org/
[9] https://github.com/datmo/datmo
[10] https://github.com/quantopian/qgrid
[11] https://www.kaggle.com/thedownhill/art-images-drawings-painting-sculpture-engraving
[12] Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image recognition." ar
