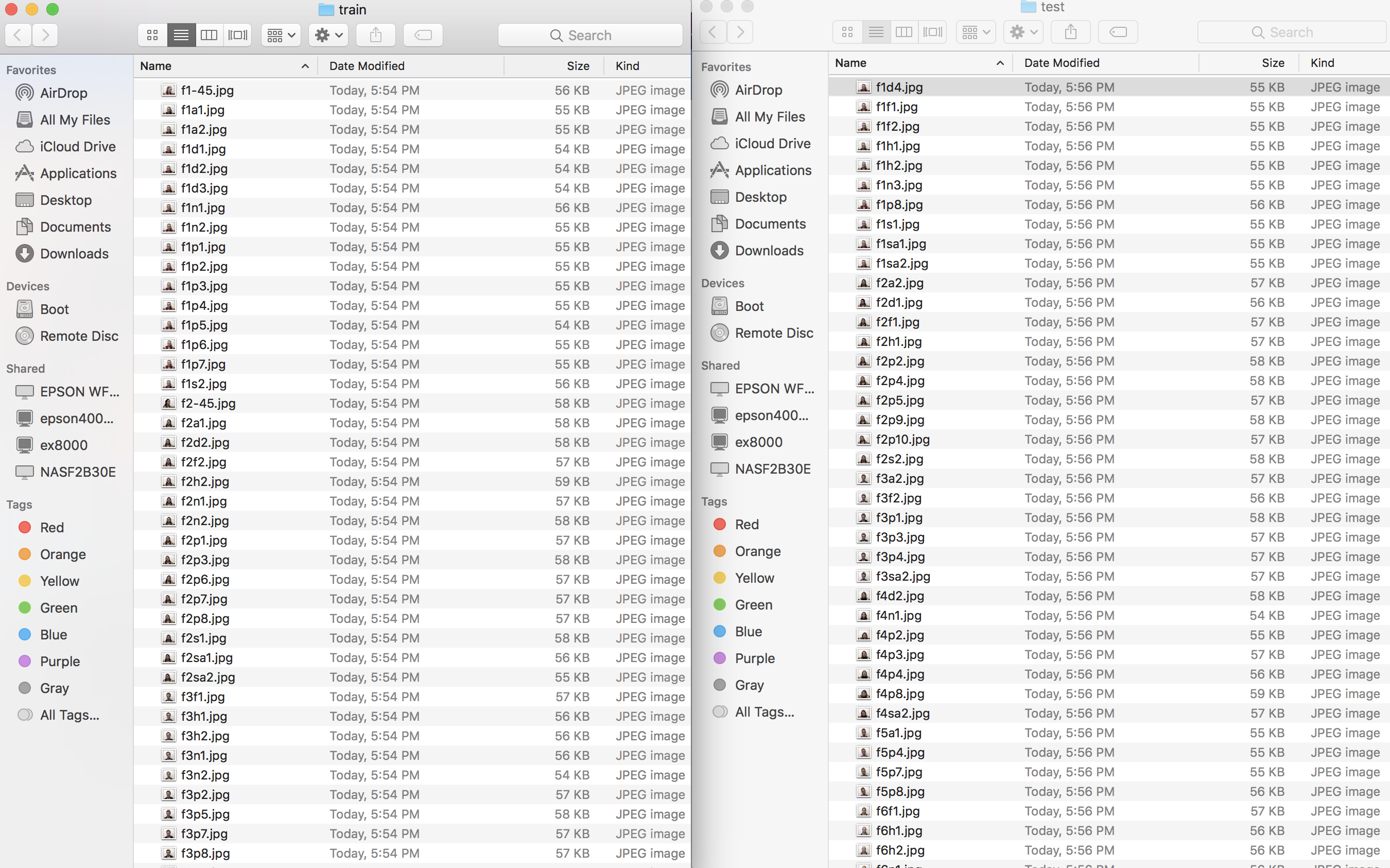
Organizing files in train/test directories

For a prototype model I'm writing that involves a multi-class problem with facial images, I've found the need to use some basic Python code to organize my image files and partition them into train and test directories. I thought it might be helpful to post this in case others need this to shuffle around their files.
Here we have three classes - NONE, MODERATE, SEVERE.
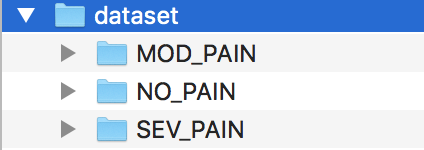
Write all the filenames to a text file
none_path = ".../images/dataset/NO_PAIN"
none_txt_path = ".../images/foo.txt"
def write_filenames(img_path, text_path):
dirList=os.listdir(path)
with open(text_path, "w") as f:
for filename in dirList:
print(filename.rsplit( ".", 1 )[0])
f.write("%s\n" % filename.rsplit( ".", 1 )[0])
return f
write_filenames(none_path, none_txt_path)
You can rerun this function write_filenames in order to return a .txt file for each of the directories we have for images for each of the three classes, like so:
write_filenames(moderate_path, moderate_txt_path)
write_filenames(moderate_path, moderate_txt_path)
You'll notice in this specific example above, using rsplit removes the file extension which in this case is .jpg.
If you use the below function, it preserve the file extension which will be important for using shutil later on.
With the file extension
def write_filenames_wext(img_path, text_path):
dirList=os.listdir(path)
with open(text_path, "w") as f:
for filename in dirList:
print(filename)
f.write("%s\n" % filename)
return f
write_filenames_wext(none_path, none_txt_path)
Again, with this you can run the function again for each of the three classes, run it again for moderate and severe.
Put all file names into a dataframe
This part is super easy. Using `pandas`, we use `read_table` to read in all the files names we wrote to each of our three text files. We assign a column header name called "file" for each of the filenames, then add a new column called "class". Then we `append` each of the dataframes together (I usually using `len` to count up the records to ensure the final `data_wext` is correct) for our final dataframe.import pandas as pd
none_wext = pd.read_table(".../face/NON_fn.txt", names=['file'])
mod_wext = pd.read_table(".../face/MOD_fn.txt", names=['file'])
sev_wext = pd.read_table(".../face/SEV_fn.txt", names=['file'])
none_wext['class'] = 'NONE'
mod_wext['class'] = 'MOD'
sev_wext['class'] = 'SEV'
df1_wext = none_wext.append(mod_wext)
data_wext = df1_wext.append(sev_wext)
data_wext.to_csv(".../face/allfaces_w_ext.csv", index=0)
Train/Test Split
Since you can see that the entire final dataframe is in order of the classes, we need to shuffle them and split this dataset into a train and test set. We'll use the `scikit-learn` split function for this. The default is `shuffle=true`.from sklearn.model_selection import train_test_split
X = data_wext['file']
y = data_wext['class']
Here's a sample of our X of only the filenames with their extensions:
Here's a sample of our y of labels that are not shuffled, still in the original order:

Now let's split it 33%:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
Here's a sample of X_train:
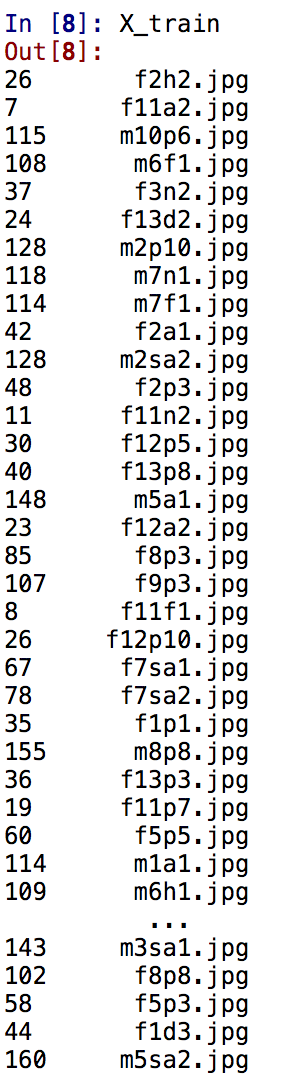
And, here's a sample of y_train which we can see is now shuffled:

At this point, we need to convert our pandas.series into lists so that we can iterate through this list to use shutil.
X_train_l = X_train.tolist()
X_test_l = X_test.tolist()
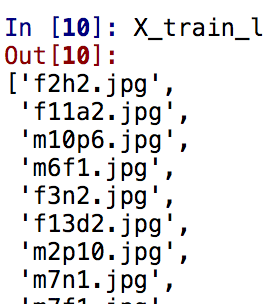
Copy the training and test set to their own directories
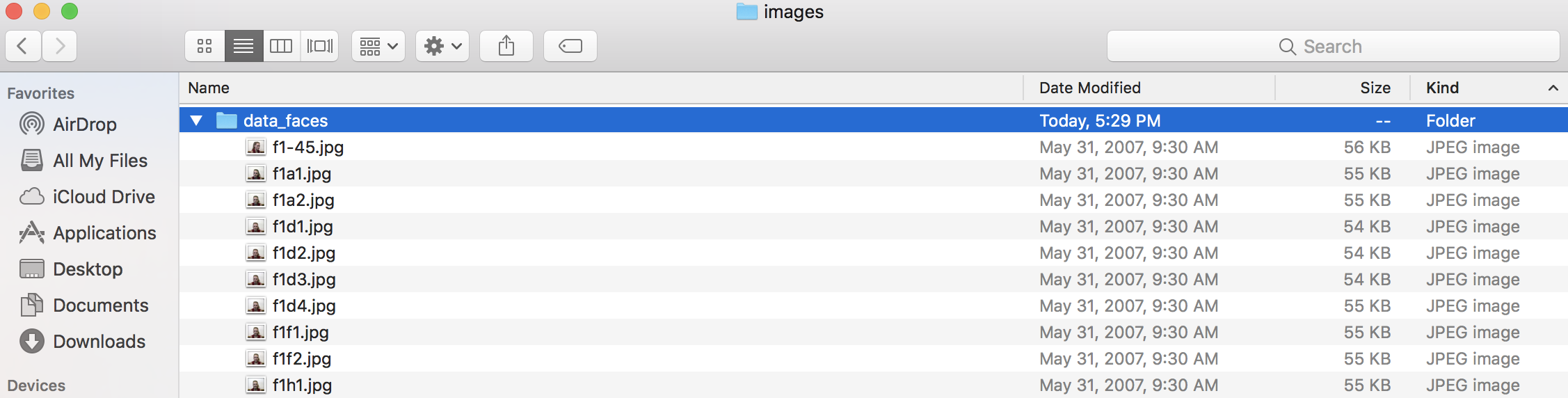
Here, what we need to do is use our X_train and X_test lists to copy over only the files in each of these lists into new directories called `train` and `test`.So here's our original directory called data_faces:
Only for those files in the lists for X_train and X_test, we want to copy them from data_faces (our source) and move them into two empty directories, train and test.

import os
import shutil
src = '.../face/images/data_faces' #source of all images
dest_test = '.../face/images/test' #test folder
dest_train = '.../face/images/train' #train folder
#move to train
for file in os.listdir(src):
if file in X_train_l:
name = os.path.join(src, file )
if os.path.isfile( name ) :
shutil.copy( name, dest_train)
else :
print 'file does not exist', name
#move to test
for file in os.listdir(src):
if file in X_test_l:
name = os.path.join(src, file )
if os.path.isfile( name ) :
shutil.copy( name, dest_test)
else :
print 'file does not exist', name
Now you have two directories - one for train and one for test, which you can use for modeling.