Amazon Food Reviews, Part IV

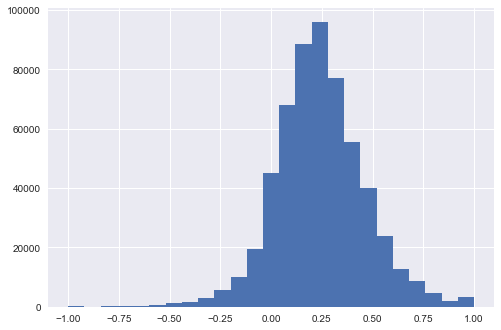
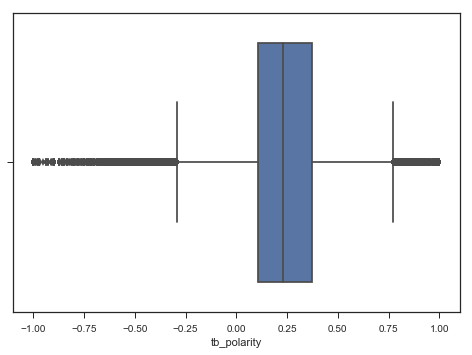
In Part I we did some exploratory analysis after using the TextBlob package to apply sentiment scores using its polarity method. We found the mean sentiment was around .24 and then spilt up the dataframe into five calendar years of review from 2008 to 2012, getting a better sense of how much of the total reviews account for the outliers of "perfectly positive" (1.0) and "perfectly negative" (-1.0) polarity.

In Part II, we did a deeper dive into these reviews of extreme sentiments and confirmed that a very small number of reviews have such extreme polarity scores: 0.005 of all reviews have 1.0 positive sentiment, and 0.0005 of all reviews have -1.0 negative sentiment. However, after manually inspecting some of the reviews, we learned that the TextBlob polarity score isn't perfect in and of itself, and many obviously negative reviews were given 1.0 positive polarity score.

In Part III, we reviewed the Top 25 features for perfectly positive reviews, based on Amazon Scores of 1 to 5. Using scikit-learn's CountVectorizer() and TfidfVectorizer(), with a Naive Bayes classifier, we were able to retrieve the Top 25 features. The utility here is that it gives us a general sense of the infrequent but informative words mentioned in reviews that had +1.0 sentiment.
courtesy of http://vialab.science.uoit.ca/wp-content/uploads/2016/12/VIS4DH-DocAna-Combined-Lecture-1.pdf
Now, in Part IV, we continue our deep dive focusing just on the perfectly positive and negative comments. Using NLTK, we're going to return trigrams for comments where the polarity sentiment is: 1.0 positive and Score = 5, and -1.0 negative and Score = 1. So, the "most positive of the positive" and "the most negative of the negative".
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from nltk.tokenize import RegexpTokenizer
For all comments with perfectly 1.0 positive sentiment
#tokenize and remove punctuation
copy1 = pf_posr[['ProductId', 'text_cln', 'Score']].copy()
#tokenize
tokenizer = RegexpTokenizer(r'\w+')
copy1['text_cln'] = copy1['text_cln'].map(lambda x:
tokenizer.tokenize(x))
cachedstopwords = stopwords.words('english')
stw_set = set(cachedstopwords)
copy1['_cln'] = copy1.apply(lambda row: [item for item in
row['text_cln'] if item not in stw_set], axis=1)
#sum up all comments where the Score is 5 Stars
copy1sum = ((copy1.loc[(copy1['Score'] == 5)]).reset_index())._cln.sum()
For all comments with perfectly -1.0 negative sentiment
#make a copy
copy2 = pf_negr[['ProductId', 'text_cln', 'Score']].copy()
#tokenize the reviews
copy2['text_cln'] = copy2['text_cln'].map(lambda x:
tokenizer.tokenize(x))
#remove stopwords
copy2['_cln'] = copy2.apply(lambda row: [item for item in
row['text_cln'] if item not in stw_set], axis=1)
#sum up all comments where the Score is 1 Star
copy2sum = ((copy2.loc[(copy2['Score'] == 1)]).reset_index())._cln.sum()
Now copy1sum and copy2sum (example below) consists of all the tokenized words with stopwords removed for all reviews where polarity=1 & score=5, and polarity=-1 & score=1.
u'It',
u'taste',
u'like',
u'melted',
u'velveta',
u'nothing',
u'else',
u'This',
u'tea',
u'tastes',
u'nasty',
u'Maybe',
u'I',
u'dont',
u'like',
u'sage',
u'made',
u'gag',
u'Opened',
u'set',
u'expire',
u'another',
u'year',
u'awful',
u'rancid',
u'smelling',
u'Rancid',
u'grains',
u'toxic',
u'terribly',
u'irresponsible',
...]
Here, I apply the Point-Wise Mutual Information (PMI) method in the trigrams function. In the nltk documentation, it references, "Scores ngrams by pointwise mutual information, as in Manning and Schutze 5.4", which Googled here to Stanford University's keystone publication: January 7, 1999 Christopher Manning & Hinrich Schütze.

"This type of mutual information, which we introduced in Section 2.2.3, is roughly a measure of how much one word tells us about the other, a notion that we will make more precise shortly." However, after reading the Section 5.4, it seems that PMI doesn't work well with low volumes of documents. It works better when there are lots (the example cites 23,000) of documents. Per the article, "None of the measures we have seen works very well for low-frequency events. But there is evidence that sparseness is a particularly difficult problem
for mutual information."
In this case, the positive reviews include 2,888 reviews, and the negative reviews include 303 reviews. It's also worth noting that trigrams work better with a large set of text documents, as well.
def trigram(sum_text):
tgm = nltk.collocations.TrigramAssocMeasures()
finder = nltk.collocations.TrigramCollocationFinder.from_words(sum_text)
scored = finder.score_ngrams(tgm.pmi)
phrases = pd.DataFrame(scored)
print(phrases)
phrases.hist(bins=25)
plt.show()
trigram(copy1sum)
trigram(copy2sum)
Trigrams for Polarity = 1, Score = 5
0 (07, Yogurt, Maker) 30.427120
1 (29, 95, El) 30.427120
2 (95, El, Fenix) 30.427120
3 (ABOUT, ANYTHING, BRINGS) 30.427120
4 (AFTER, DOING, QUITE) 30.427120
5 (Al, Dente, Spinach) 30.427120
6 (BP, Cholestrol, Calories) 30.427120
7 (BUYI, RECOMEND, READ) 30.427120
8 (Barswould, helpful, contolling) 30.427120
9 (Bean, Roastery, Sampler) 30.427120
10 (Birmingham, Alabama, salted) 30.427120
11 (Blend, Mueslix, Raisins) 30.427120
12 (Buffet, motel, Branson) 30.427120
13 (CAPSULE, FORM, GUMMIES) 30.427120
14 (CHEDDAR, BASED, BUNNY) 30.427120
15 (COSTUMER, SEVICE, FASY) 30.427120
16 (Chinatown, Washington, DC) 30.427120
17 (Corny, Puffy, Puffiness) 30.427120
18 (Crispbread, Multi, Grain) 30.427120
19 (Crispy, Blend, Mueslix) 30.427120
20 (Crown, Prince, Baby) 30.427120
21 (David, Rio, Orca) 30.427120
22 (Dente, Spinach, Fettuccine) 30.427120
23 (Dusted, Belgian, Truffles) 30.427120
24 (EGGS, MEATLOAF, SPAGHETTI) 30.427120
25 (FOLGERS, GOURMET, SUPREME) 30.427120
26 (Frank, McReynoldsCarmichael, CA) 30.427120
27 (GEM, HGHLY, RECCOMEND) 30.427120
28 (Grace, Leaving, Home) 30.427120
29 (HER, SOILDER, FRIEND) 30.427120
The results here provide us the first steps of understanding some of the food products users are reviewing which they've assigned an Amazon Score of 5, and that our sentiment score has rated as perfectly positive. Glancing at these top 25 trigrams, it looks like products ranging from Folgers coffee to Mueslix with raisins rank as highly rated. Another step we could take after this investigation is to specifically focus on collocations with the word 'recommend', 'recommended', 'recommending' (use a Porter Stemmer), to figure out which products are being mentioned as highly recommended. I'll note that as the TF-IDF scores decrease, around the 20-ish range, more phrases with verbs emerge talking about actions. The lower range closer to 0.00 typically consist of phrases like 'I - great - service', indicating some blunter phraseology, albeit with less lexical diversity.
Trigrams for Polarity = -1 and Score = 1
0 (00would, credited, credit) 23.933732
1 (11, dollars, equates) 23.933732
2 (2010, PLEASE, DON) 23.933732
3 (31, 36, 22) 23.933732
4 (36, 22, 97) 23.933732
5 (AKC, labelin, display) 23.933732
6 (Always, burned, chemical) 23.933732
7 (Beware, Pop, Chips) 23.933732
8 (Buyer, Beware, Pop) 23.933732
9 (CAKE, MIX, TASTES) 23.933732
10 (CANCEL, Prime, Membership) 23.933732
11 (Chips, basically, horribly) 23.933732
12 (Daniels, SW, Mustard) 23.933732
13 (Ecuador, technology, hygiene) 23.933732
14 (Energy, Pro, Taurine) 23.933732
15 (Gingerbread, Spicy, Eggnog) 23.933732
16 (Gourmet, Popcorn, Pecan) 23.933732
17 (Hansen, Energy, Pro) 23.933732
18 (However, half, crumbled) 23.933732
19 (Jack, Daniels, SW) 23.933732
20 (June, 2010, PLEASE) 23.933732
21 (LITERALLY, THEY, TASTE) 23.933732
22 (Look, crazy, misleading) 23.933732
23 (MIX, TASTES, LIKE) 23.933732
24 (Marshall, Creek, Spices) 23.933732
25 (Me, Co, workers) 23.933732
26 (Munchos, baked, potato) 23.933732
27 (NEGATIVE, STAR, RATING) 23.933732
28 (PACKAGE, OF, FOUR) 23.933732
29 (PLEASE, DON, T) 23.933732
Now this is the baddest of the bad. These are the reviews that users scored as 1 star and that our sentiment polarity scored as -1.0. Well, it looks like some users don't really like Pop Chips, as well as mustard, eggnog, popcorn, and Munchos (hm?), and unsurprisingly have issues with the taste of products. Some trigrams here, as usually occurs with negative sentiment, indicate how people star USING ALL CAPS LIKE THIS when they feel particularly emphatic. One trigram even picks up on how the user [9] may cancel their Prime membership (I'd never cancel mine, big time life saver!).