Amazon Food Reviews, Part III

Now that we know a little about the extremes of perfectly positive and negative sentiment reviews, let's analyze some key features of the text. Here we'll allow a user to retrieve the top 25 text features based on inputting an Amazon Score of 1 to 5 for only the set of 2,888 perfectly positive reviews.
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
#Generating feature set:
count_vect = CountVectorizer(decode_error='ignore', strip_accents='unicode', stop_words='english')
X_train_counts = count_vect.fit_transform(pf_posr['text_cln'])
feature_names = count_vect.get_feature_names()
With CountVectorizer() we are converting a collection of text documents (in this case, the 2,888 reviews) to a matrix of token counts. This transforms these 2,888 documents into a document-term matrix.
#TF-IDF
tfidf_transformer = TfidfTransformer()
X_train_tfidf = tfidf_transformer.fit_transform(X_train_counts)
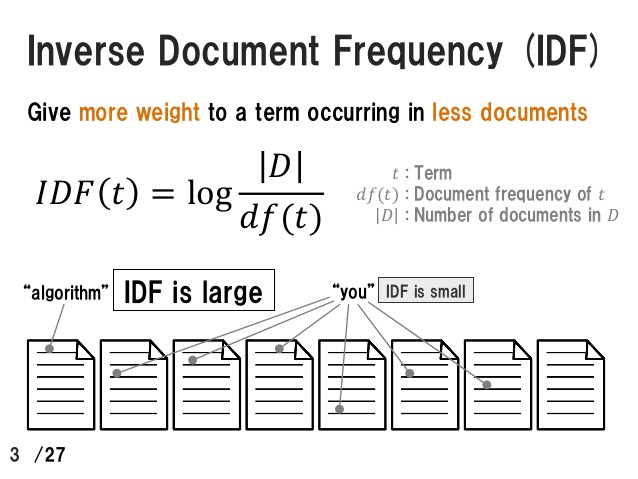
The TF-IDF vectorizer then normalizes the results of Count Vectorizer and computes it as the term frequency, per sklearn, "the number of times a term occurs in a given document, is multiplied with idf component, which is computed as:
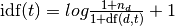
And normalized by the Euclidean norm:
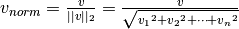
A succinct overview of TF-IDF: https://www.slideshare.net/MasumiShirakawa/www-48698138
#Training model using NBM
clf = MultinomialNB().fit(X_train_tfidf, pf_posr['Score'])
We use a Naive Bayes classifier against 5 Amazon scores. Here our target is the Amazon Score (1 to 5 star-rating), and the features is the TFIDF transformed 2,888 comments.
#Sort the coef_ as per feature weights and select largest 25 of them
def topfeatures(score):
inds = np.argsort(clf.coef_[score, :])[-25:]
print("The top 20 most informative words for category:", score, "which is a", score+1, "star rating:")
for i in inds:
f = feature_names[i]
c = clf.coef_[score,[i]]
print(f,c)
topfeatures(0) #1-star rating
topfeatures(1) #2-star rating
topfeatures(2) #3-star rating
topfeatures(3) #4-star rating
topfeatures(4) #5-star rating
#look up 1.0 polarity based on star ratings
#reviewed the mention of specific products in the 'Summary' feature
#not all the Top 25 features are indicative of the pictured product; the pictured product is just one of several mentioned for the specific score
pf_posr.loc[(pf_posr['Score'] ==1)]

Top 25 Features for 1-Star from Comments with 1.0 Polarity
The top 20 most informative words for category: 0 which is a 1 star rating:
threw [-7.79996899]
coffee [-7.7951422]
organic [-7.78958907]
china [-7.77283025]
away [-7.76645117]
sugar [-7.76579685]
best [-7.75345818]
orally [-7.74445683]
fixated [-7.74445683]
ordered [-7.73832205]
recieved [-7.727158]
ok [-7.69296289]
perfect [-7.68821702]
money [-7.67964082]
starbucks [-7.67337517]
amazon [-7.66749179]
lab [-7.6652918]
cup [-7.64713075]
im [-7.61373087]
buy [-7.58818984]
don [-7.56828648]
product [-7.54156223]
thought [-7.53127323]
trying [-7.52575018]
oatmeal [-7.43118594]

Top 25 Features for 2-Star from Comments with 1.0 Polarity
The top 20 most informative words for category: 1 which is a 2 star rating:
tho [-8.07454088]
great [-8.07432575]
pumpkin [-8.06600608]
did [-8.06138974]
10 [-8.02995606]
melt [-8.02656214]
guess [-8.01872103]
msg [-8.0172391]
requires [-8.01217927]
needs [-8.00529997]
scale [-7.99903662]
restrict [-7.99198244]
bait [-7.98685153]
taste [-7.98554735]
torrone [-7.9801805]
caned [-7.97789598]
watery [-7.97789598]
straining [-7.97789598]
libby [-7.97789598]
altering [-7.97789598]
crackers [-7.90028079]
organic [-7.89764661]
don [-7.89348715]
like [-7.83583547]
didn [-7.83501837]

Top 25 Features for 3-Star from Comments with 1.0 Polarity
The top 20 most informative words for category: 2 which is a 3 star rating:
great [-7.48541701]
make [-7.47295349]
excellent [-7.39944239]
hydrogenated [-7.39217339]
kernel [-7.39217339]
palm [-7.39217339]
ph [-7.37936449]
cottonseed [-7.37936449]
home [-7.35011242]
products [-7.33938389]
good [-7.32709638]
try [-7.3092654]
delivery [-7.29651867]
gave [-7.22712887]
stars [-7.22347376]
just [-7.20047378]
company [-7.18506426]
aroma [-7.18105323]
coffee [-7.16372848]
reviews [-7.14811634]
oil [-7.13532256]
style [-7.12093234]
expecting [-7.11638945]
terms [-7.10562938]
reputation [-7.08088134]

Top 25 Features for 4-Star from Comments with 1.0 Polarity
The top 20 most informative words for category: 3 which is a 4 star rating:
gluten [-7.11855549]
did [-7.09385228]
sensitivities [-7.04143962]
ve [-6.94590483]
lot [-6.9344587]
cup [-6.92053735]
just [-6.91590761]
yum [-6.90335816]
flavor [-6.89948774]
happy [-6.88787952]
stop [-6.88502734]
great [-6.88293477]
perfect [-6.86068608]
alot [-6.85952787]
pick [-6.84420012]
jerky [-6.84015972]
snacks [-6.8373819]
wanting [-6.8195902]
trips [-6.80368821]
best [-6.78151744]
road [-6.74992527]
caramel [-6.66617531]
delicious [-6.64981578]
coffee [-6.60708926]
product [-6.52554785]

Top 25 Features for 5-Star from Comments with 1.0 Polarity
The top 20 most informative words for category: 4 which is a 5 star rating:
tasting [-6.02227077]
dog [-5.98333529]
don [-5.95298495]
tried [-5.92682788]
order [-5.92369162]
flavor [-5.84647964]
loves [-5.82056476]
price [-5.80849558]
taste [-5.76613348]
use [-5.74784248]
time [-5.73274083]
buy [-5.68287917]
ve [-5.66305074]
amazon [-5.65138305]
perfect [-5.63420383]
just [-5.62838251]
wonderful [-5.55563011]
like [-5.52849757]
coffee [-5.46426497]
excellent [-5.42771861]
tea [-5.41622367]
delicious [-5.37320012]
product [-5.30711404]
great [-5.17255728]
best [-4.53205116]