Classifying business documents


In a project two years ago, I wrote a basic Naive Bayes classification script, largely from this tutorial off of scikit-learn's site, which was pretty much all that I needed.
I typically use a private company repo, but here's the script on my public Github.
One thing I really excel at is un-sexily enough, cleaning data. Me and my colleagues spend a lot of time cleaning data. And with text data, that's no exception - as you all know. But I did manage to save some time here by using a free service that converts pdf to text. Because, see, this was a project that required categorizing several hundred pdf business documents into raw text before applying the Naive Bayes.
I used this service called Sejda: https://www.sejda.com/extract-text-from-pdf. Since this was also a proof-of-concept, we were able to upload the documents to their public cloud for text extraction. Don't do this obviously if your data contains PII. Currently, I think this team is running their own pdf to text conversion.
Anyway, you can see here that the proof-of-concept was made pretty easy since I set up local directories on my laptop with four categories with the types of documents. To give you a sense of the proof-of-concept'ishness of this project, there are over almost 1000 categories.

Having done it this way, it was easy to follow the rest of the tutorial and set it up pretty similarly to sklearn's.
categories = ['Env', 'Fac', 'Med', 'Saf']
arims_data = sklearn.datasets.load_files('/Users/catherineordun/Documents/ARIMS/arimsdata', categories=categories, load_content=True, shuffle=True, encoding='utf-8', decode_error='ignore', random_state=42)
X, y = arims_data.data, arims_data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
After this, set up the cross validation, and like the tutorial set up three pipelines.
def evaluate_cross_validation(clf, X, y, K):
cv = KFold(len(y), K, shuffle=True, random_state=0)
scores = cross_val_score(clf, X, y, cv=cv)
print(scores)
print("Mean score:{0:.3f}(+/- {1:.3f})".format(np.mean(scores),sem(scores)))
Three pipelines that focus on three different types of vectorizers: CountVectorizer, HashingVectorizer, and TFIDF Vectorizer.
#Creating multiple models through pipelines
clf_1 = Pipeline([
('vect', CountVectorizer(decode_error='ignore', strip_accents='unicode', stop_words='english')),
('clf', MultinomialNB()),])
clf_2 = Pipeline([
('vect', HashingVectorizer(decode_error='ignore', strip_accents='unicode', stop_words='english', non_negative=True)),('clf', MultinomialNB()),])
clf_3 = Pipeline([
('vect', TfidfVectorizer(decode_error='ignore', strip_accents='unicode', stop_words='english')),
('clf', MultinomialNB()),])
Evaluated each model, which was pretty cool:
#Evaluate each model using the K-fold cross-validation with 5 folds
clfs = [clf_1, clf_2, clf_3]
for clf in clfs:
evaluate_cross_validation(clf, arims_data.data, arims_data.target, 5)
def train_and_evaluate(clf, X_train, X_test, y_train, y_test):
clf.fit(X_train, y_train)
print("Accuracy on training set:")
print(clf.score(X_train, y_train))
print("Accuracy on testing set:")
print(clf.score(X_test, y_test))
y_pred = clf.predict(X_test)
print("Classification Report:")
print(metrics.classification_report(y_test, y_pred, target_names = arims_data.target_names))
print("Confusion Matrix:")
print(metrics.confusion_matrix(y_test, y_pred))
At this point, I decided to stick with the clf3 (the TFIDF Vectorizer):
#I chose to use model clf_3
train_and_evaluate(clf_3, X_train, X_test, y_train, y_test)
#This function generates all the features for clf_3
feature_names = clf_3.named_steps['vect'].get_feature_names()
#Returns the most informative top 20 features for each category
def most_informative(num):
classnum = num
inds = np.argsort(clf_3.named_steps['clf'].coef_[classnum, :])[-20:]
print("The top 20 most informative words for category:",classnum)
for i in inds:
f = feature_names[i]
c = clf_3.named_steps['clf'].coef_[classnum, [i]]
print(f,c)
Then, since I had four types of categories: categories = ['Env', 'Fac', 'Med', 'Saf'], I wanted to look up the most informative features for each Env: 3, Fac: 2, Med: 1, Saf: 0.
most_informative(3)
most_informative(2)
most_informative(1)
most_informative(0)
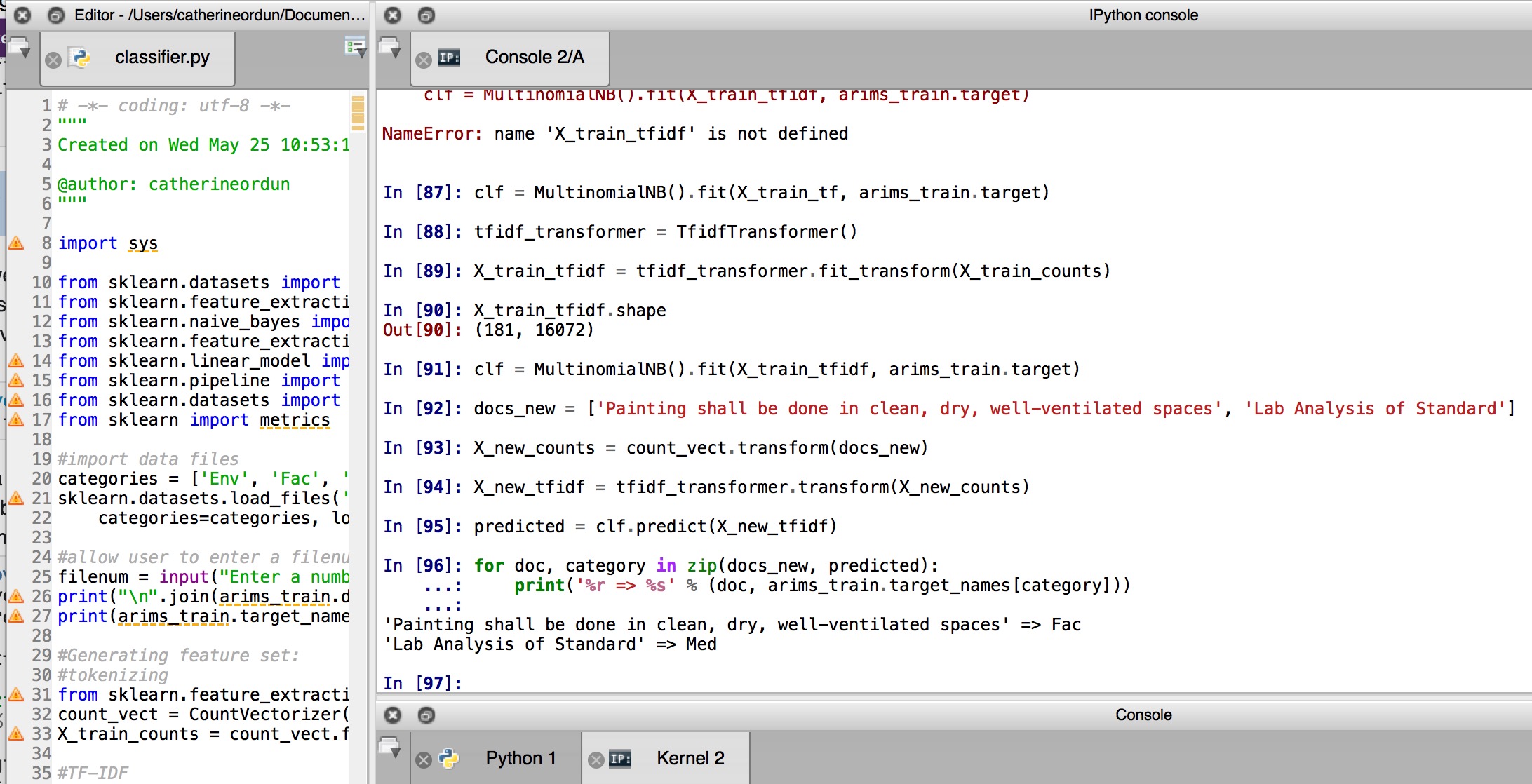
Later, using raw_input(), you can ask the user (like in a demo for your business managers), for a section of text found in one of those categories, to output the predicted category:
test_sentence = raw_input("Enter a sentence, no quotes")
docs_new = [test_sentence]
X_new_counts = count_vect.transform(docs_new)
X_new_tfidf = tfidf_transformer.transform(X_new_counts)
predicted = clf_3.predict(X_new_tfidf)
print(predicted)